
Zero to Snowflake
概述
欢迎来到Snowflake!这本入门级指南专为数据库和数据仓库管理员和架构师设计,将帮助您浏览 Snowflake 界面,并向您介绍我们的一些核心功能。注册 Snowflake 的 30 天免费试用版,并按照此实验练习进行操作。一旦我们介绍了基础知识,您就可以开始处理自己的数据,并像专业人士一样深入研究 Snowflake 的更高级功能。
先决条件:
- 使用 Snowflake 30 天免费试用环境
- 熟悉SQL、数据库概念和对象的基本知识
- 熟悉 CSV 逗号分隔文件和 JSON 半结构化数据
学习内容
- 如何创建schema、database、table、view和Virtual Warehouse。
- 如何加载结构化和半结构化数据。
- 如何对Snowflake中的数据执行分析查询,包括表之间的联接。
- 如何克隆对象。
- 如何使用Time Travel撤销错误。
- 如何创建角色和用户,并授予他们权限。
- 如何安全轻松地与其他帐户共享数据。
- 如何在 Snowflake Data Marketplace 中使用数据集。
准备实验环境
如果您尚未注册,请注册 Snowflake 30 天免费试用版。本实验的其余部分假定您使用的是通过注册试用版创建的新 Snowflake 帐户。
用于此实验的 Snowflake 版本(标准版、企业版、关键业务版等)和云提供商(AWS、Azure、GCP)和区域(美国东部、欧盟等)无关紧要。但是,我们建议您选择离您最近的区域,以及我们最受欢迎的产品 Enterprise(我们最受欢迎的产品)作为您的 Snowflake 版本。
注册后,您将收到一封电子邮件,其中包含用于访问您的 Snowflake 帐户的激活链接和 URL。
Snowflake用户界面和Lab Story
关于屏幕截图、示例代码和环境本实验中的屏幕截图描述的示例和结果可能与完成练习时看到的略有不同。
登录 Snowflake 用户界面 (UI)
打开浏览器窗口,然后输入随注册电子邮件一起发送的 Snowflake 30 天试用环境的 URL。
您应该会看到以下登录对话框。输入您在注册时指定的用户名和密码:
导航 Snowflake UI
让我们来熟悉一下Snowflake吧!本节介绍用户界面的基本组件
Worksheets
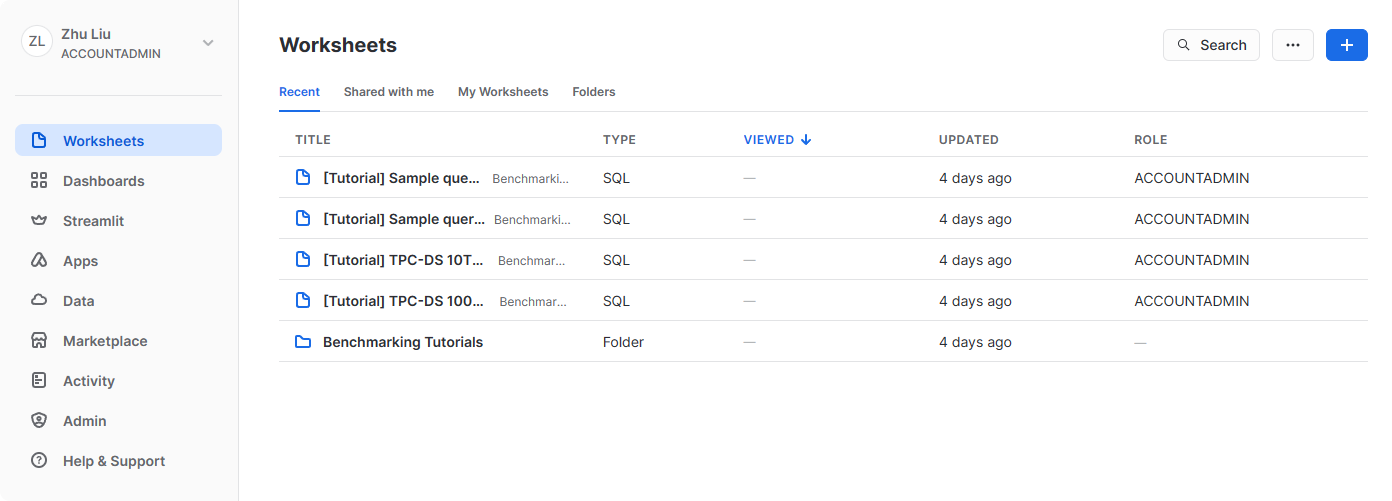
工作表选项卡提供了一个界面,用于提交 SQL 查询、执行 DDL 和 DML 操作,以及在查询或操作完成时查看结果。单击右上角的 + 即可创建一个新工作表。
Dashboard
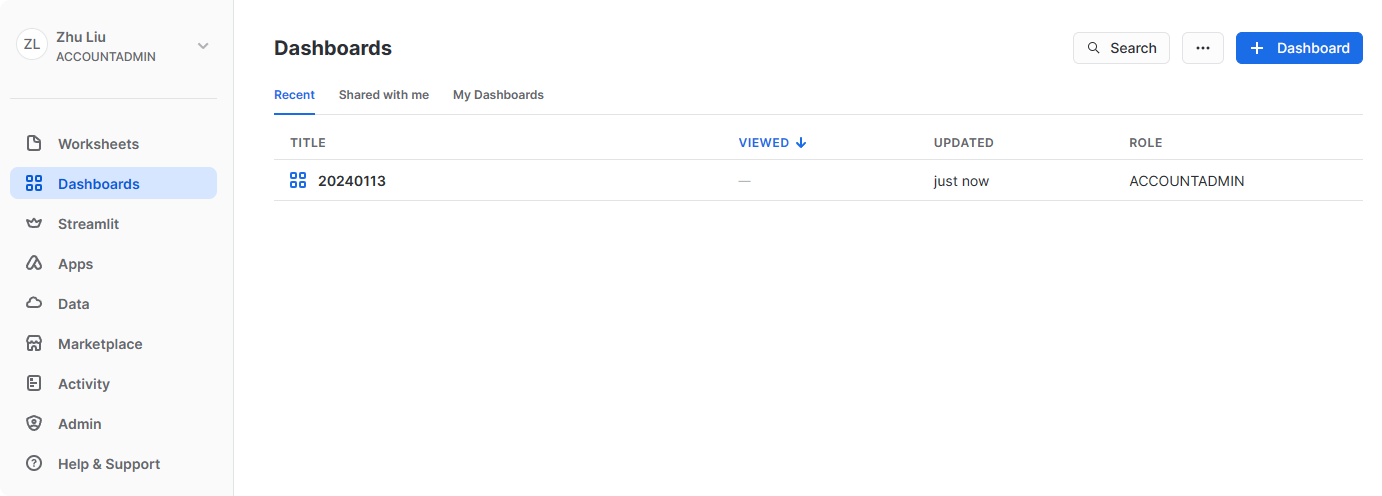
仪表板选项卡允许您创建一个或多个图表的灵活显示(以磁贴的形式,可以重新排列)。磁贴和小组件是通过执行在工作表中返回结果的 SQL查询来生成的。
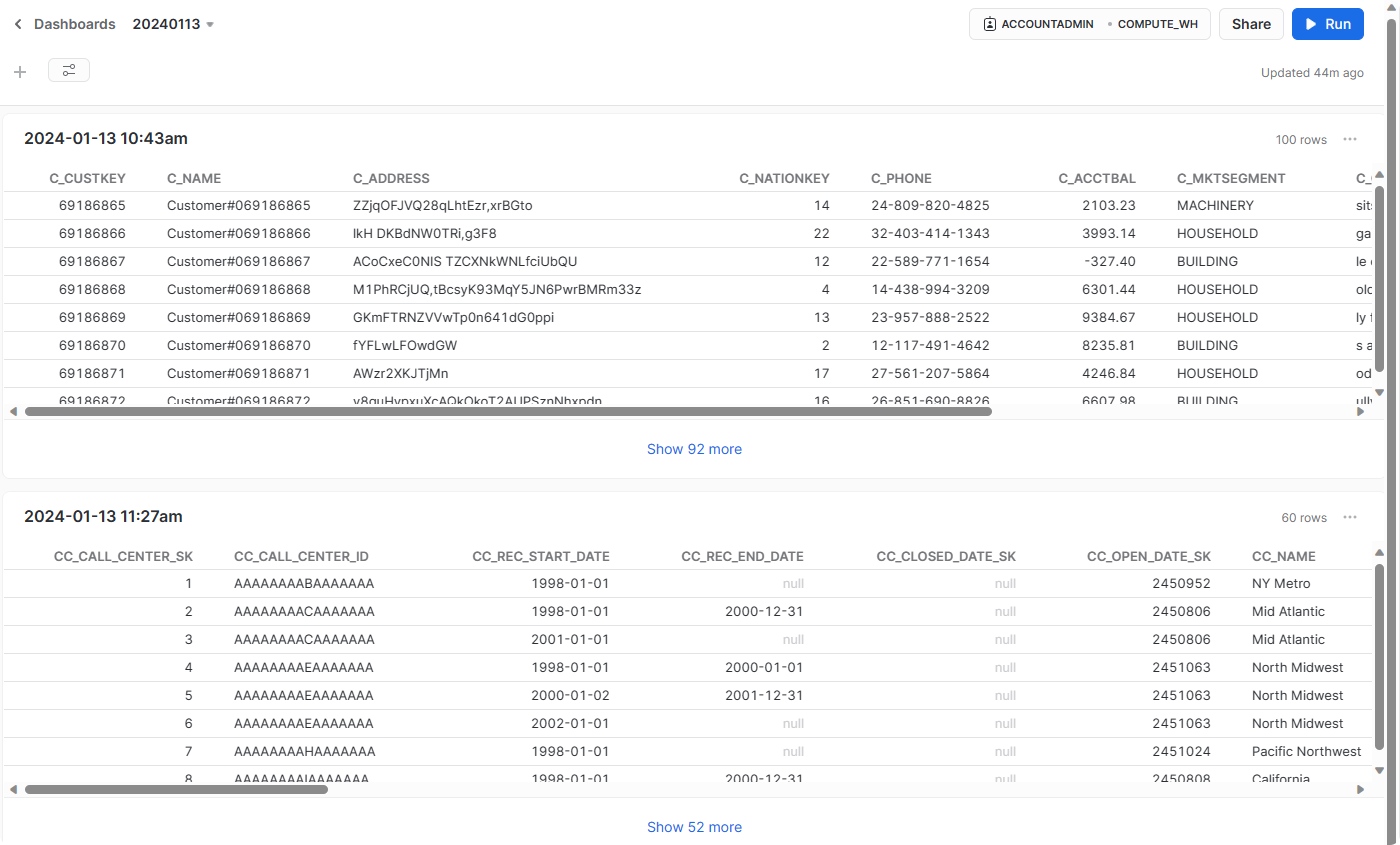
可以看到,通过仪表盘,我们可以快速地执行出预先写好的SQL语句,并以磁贴的形式展示出来。
Data
Database
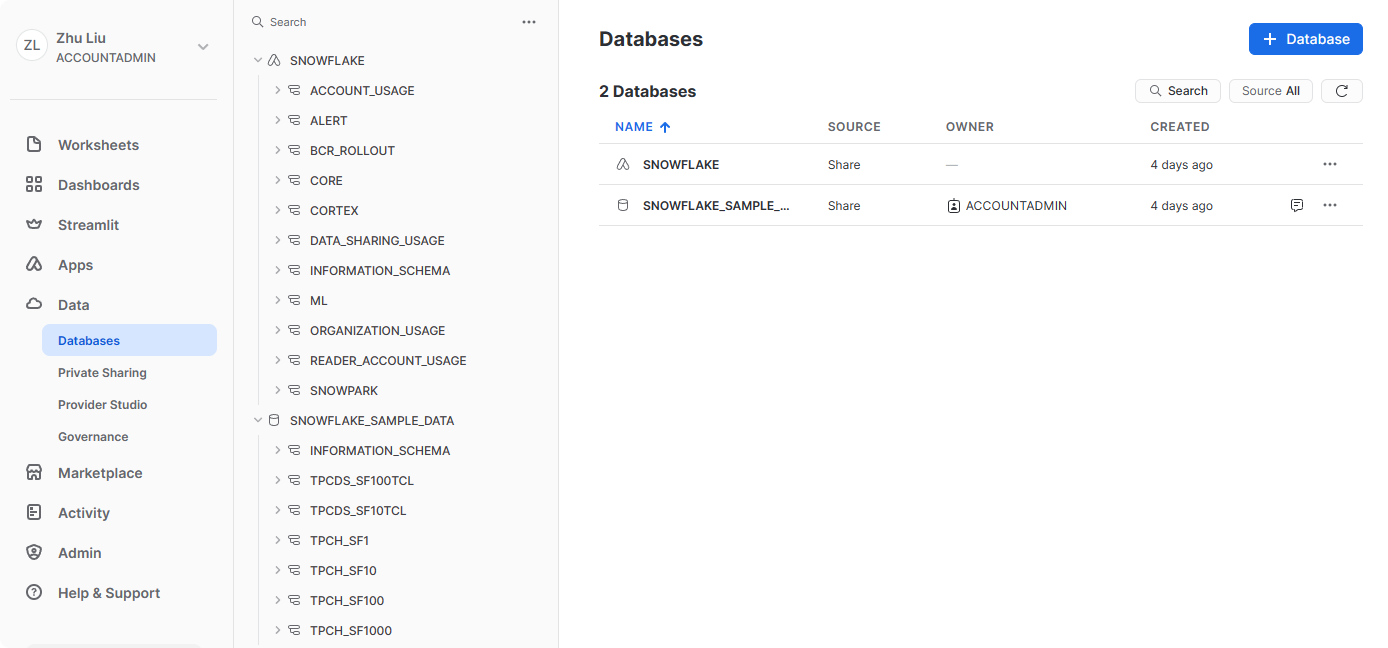
在数据下,数据库选项卡显示有关已创建或有权访问的数据库的信息。您可以创建、克隆、删除或转移数据库的所有权,以及在 UI 中加载数据。单击右上角的 + 即可创建一个新数据库。
Private Sharing
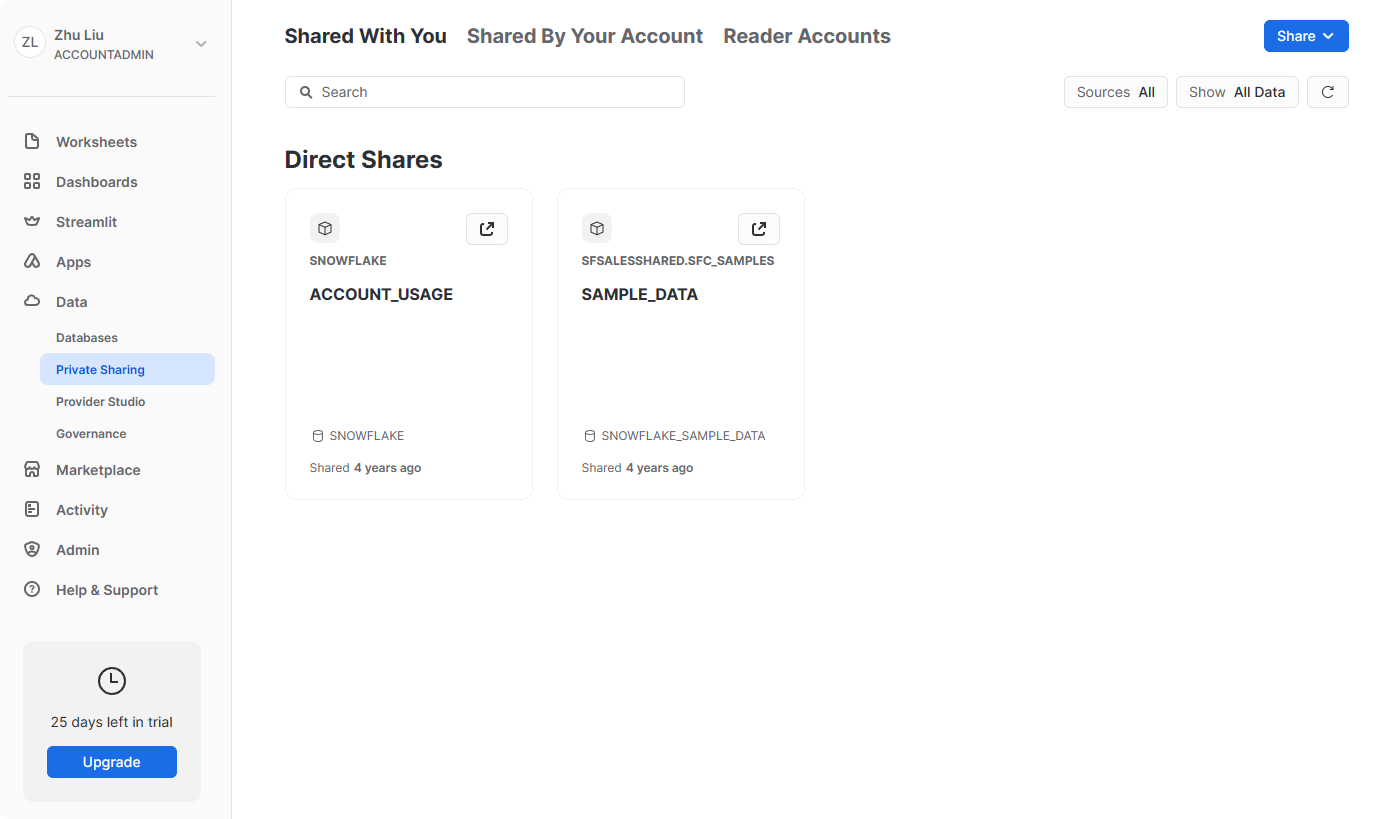
此外,在数据下,私有共享数据选项卡可以配置数据共享,以便在单独的 Snowflake 帐户或外部用户之间轻松安全地共享 Snowflake 表,而无需创建数据副本。我们将在第 10 节中介绍数据共享。
Marketplace
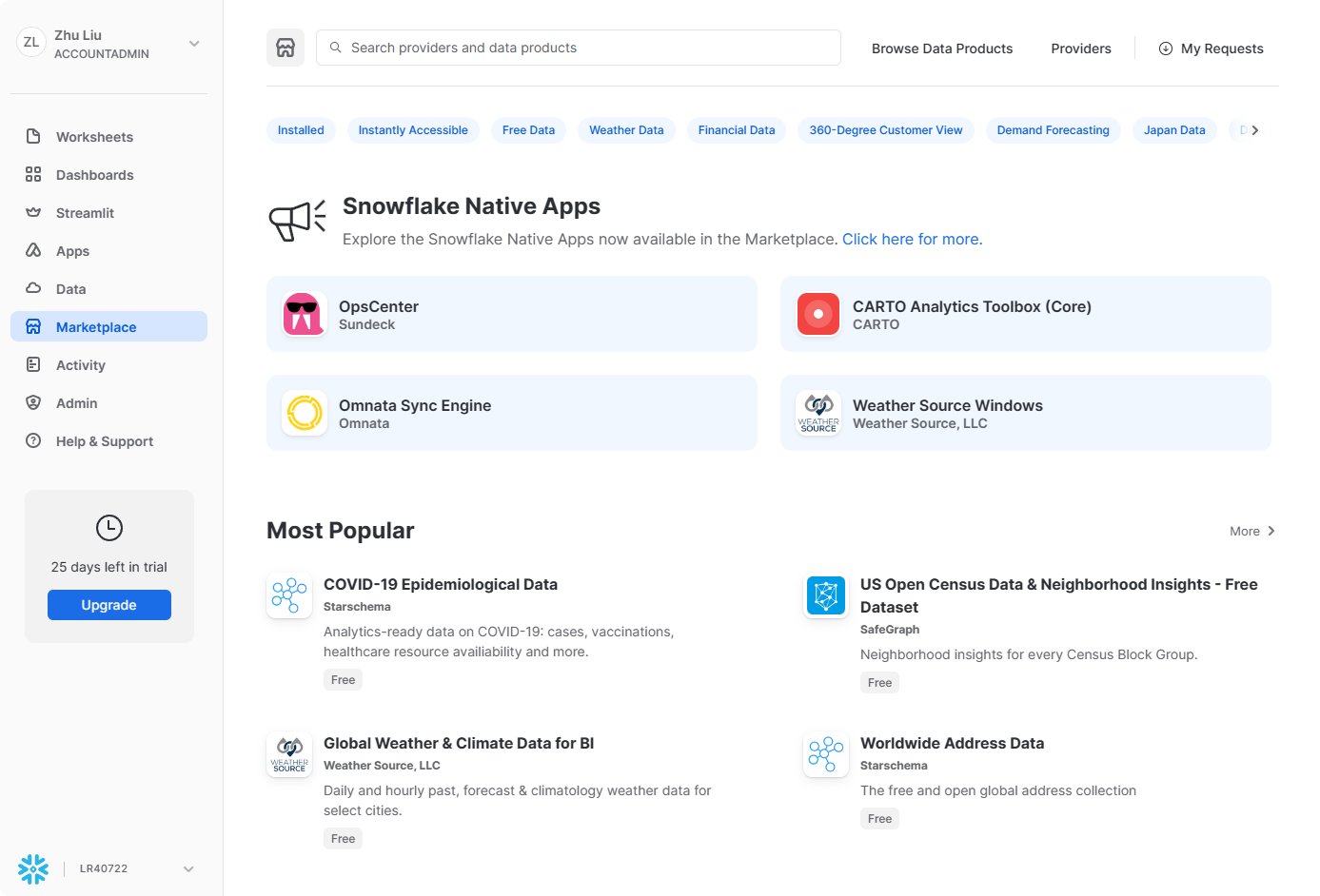
在市场选项卡中,任何 Snowflake 客户都可以浏览和使用提供商提供的数据集。共享数据有两种类型:公共数据和个性化数据。公共数据是可用于即时查询的免费数据集。个性化数据需要联系数据提供商以批准共享数据。
Activity
Query History & Copy History
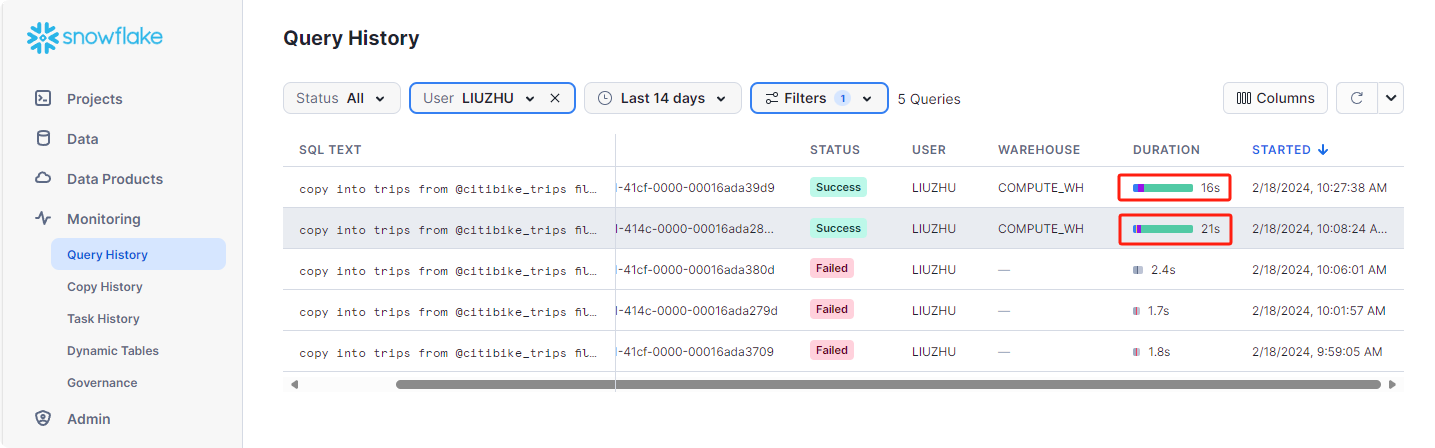
在活动下,有两个选项卡:查询历史记录和复制历史记录:
- 查询历史记录是显示以前查询的位置,以及可用于优化结果(用户、仓库、状态、查询标记等)的筛选器。查看过去 14 天内从您的 Snowflake 账户执行的所有查询的详细信息。单击查询 ID 以获取更多信息。
- 复制历史记录显示为将数据提取到 Snowflake 而运行的复制命令的状态。
Admin
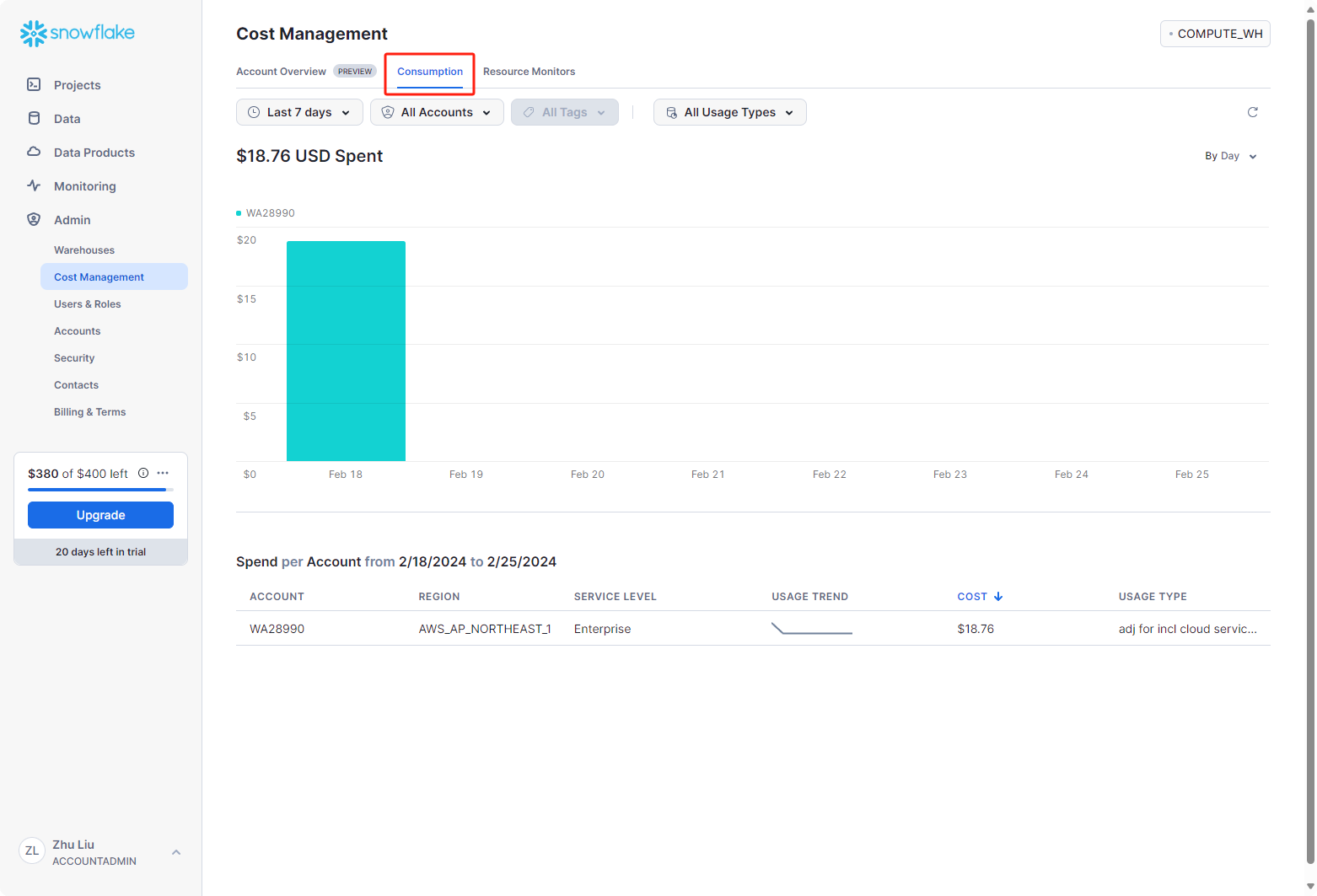
Cost Management
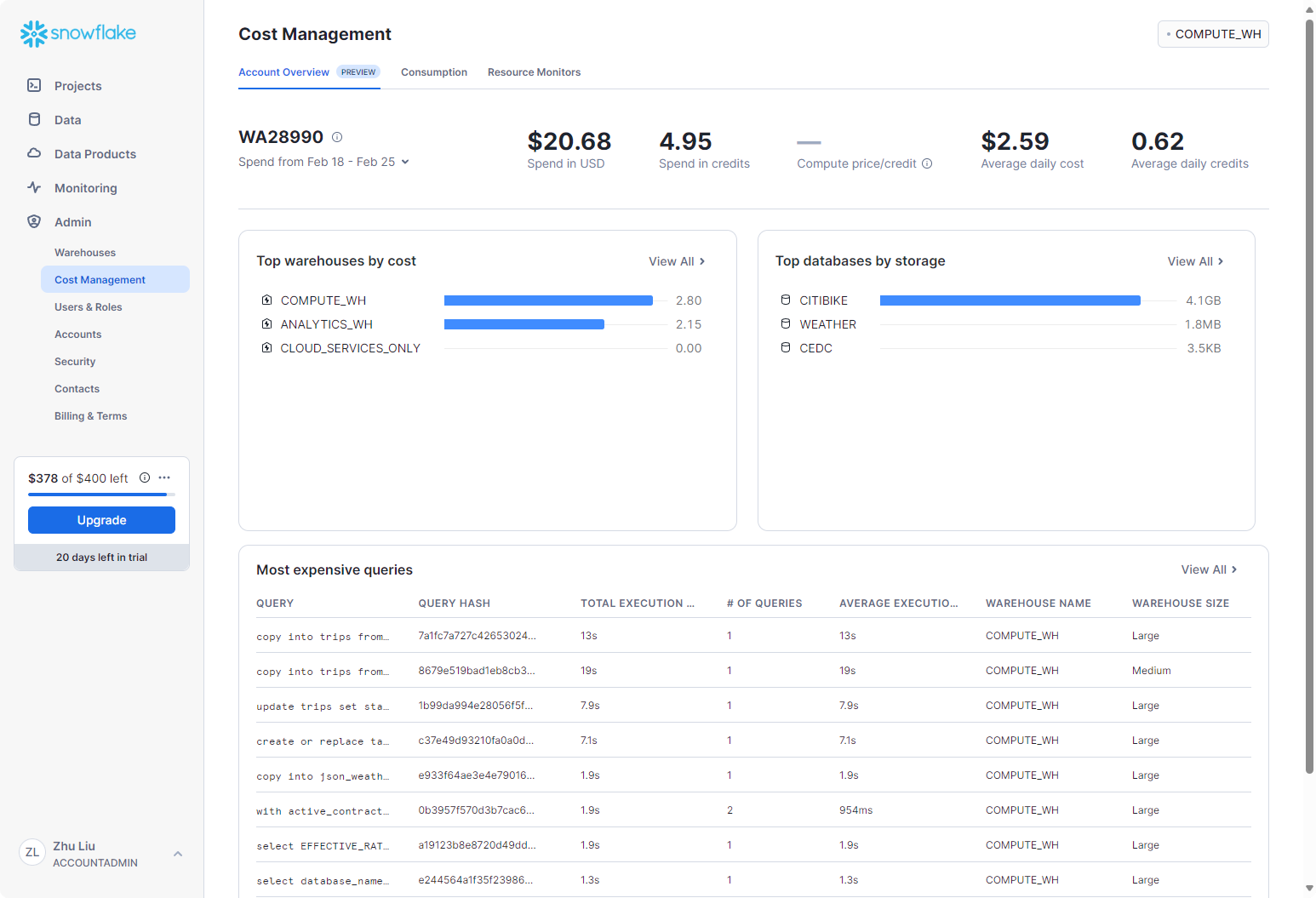
在管理员下,成本管理选项卡显示出费用的使用情况,供管理员了解成本和性价比指标。通过设置预算和资源监视器来控制支出,并发现用于优化 Snowflake 消耗的开箱即用见解。
Warehouses
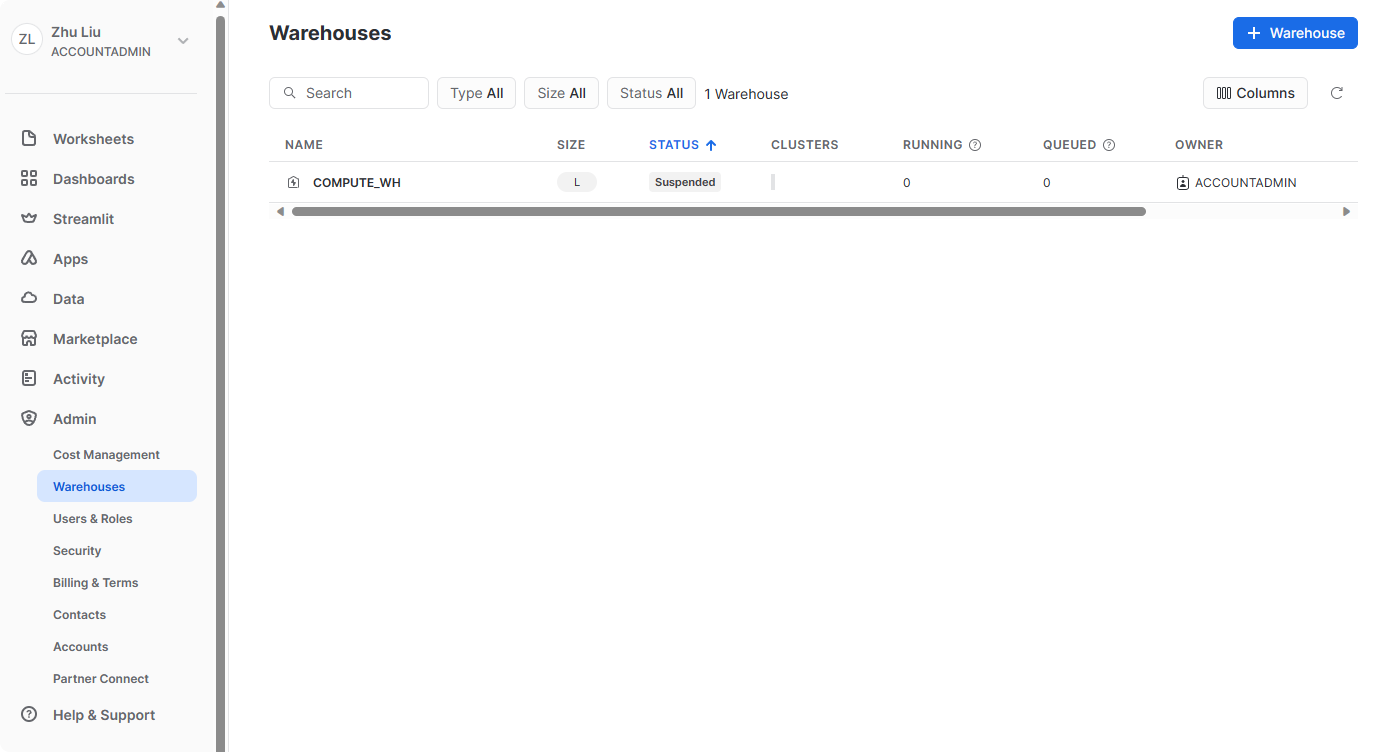
在管理员下,仓库选项卡可用于设置和管理称为虚拟仓库的计算资源,以在 Snowflake 中加载或查询数据。您的环境中已存在一个名为 COMPUTE_WH 的仓库。
Users & Roles
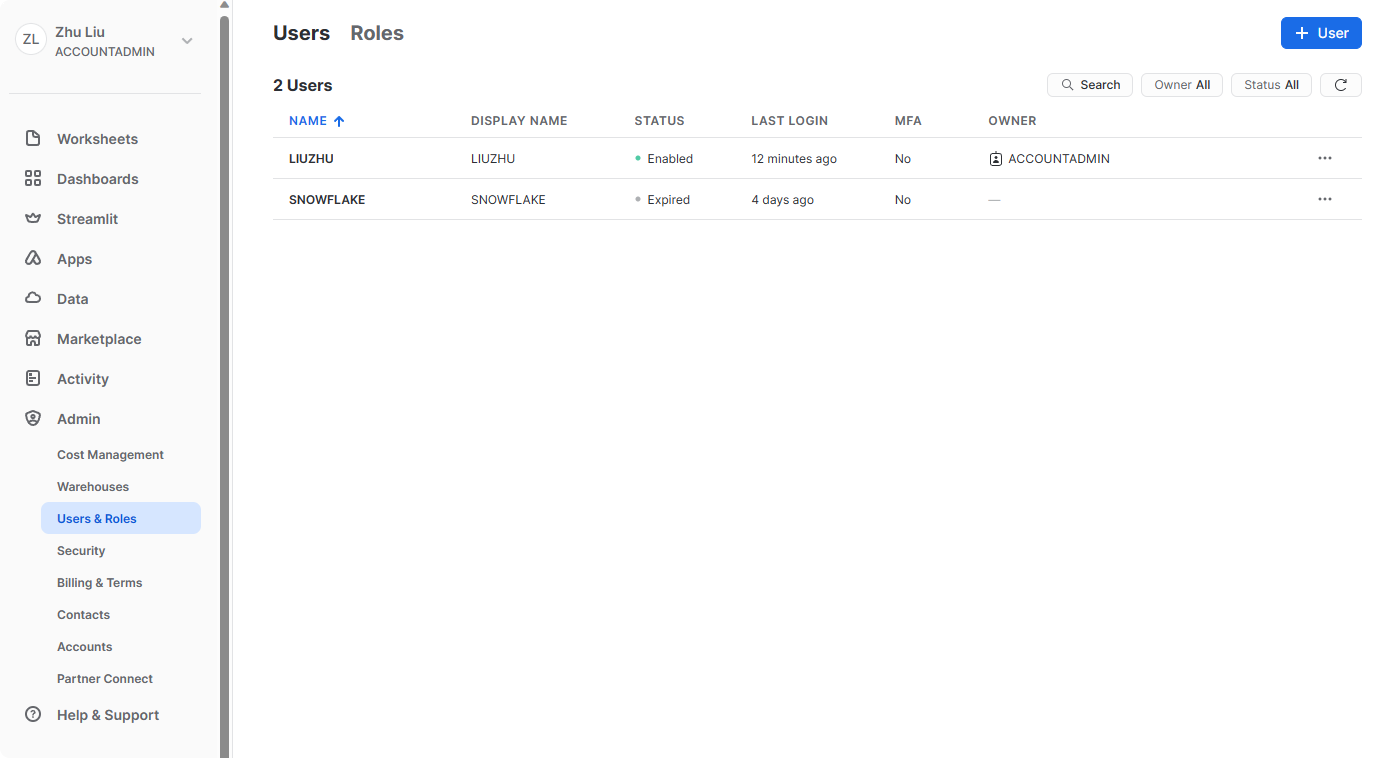
在管理员下,用户和角色选项卡的用户子选项卡显示帐户中的用户列表、默认角色和用户所有者。对于新帐户,不会显示任何记录,因为尚未创建其他角色。通过当前角色授予的权限决定了此选项卡显示的信息。若要查看选项卡上提供的所有信息,请将您的角色切换为 ACCOUNTADMIN。
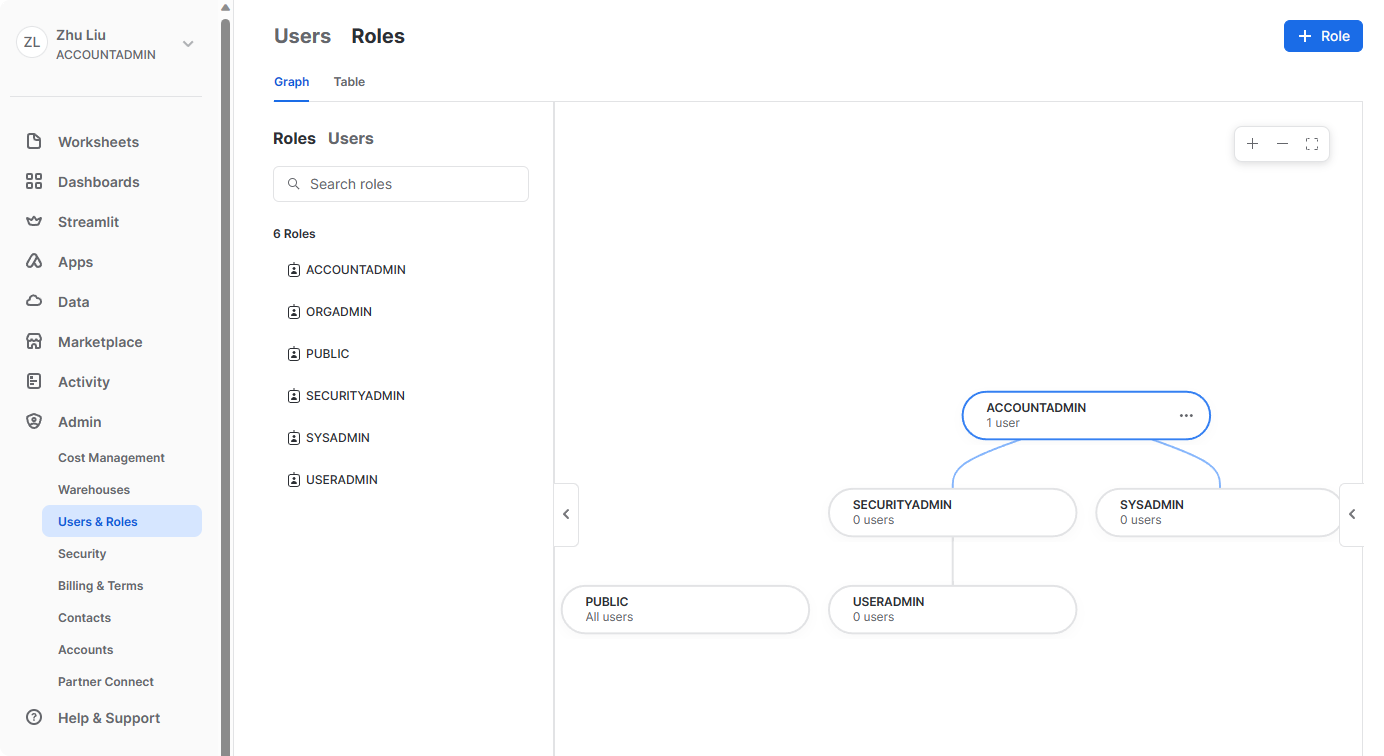
在管理员下,用户和角色选项卡的角色子选项卡显示角色及其层次结构的列表。可以在此选项卡中创建、重新组织角色并将其授予用户。还可以通过选择表子选项卡以表格/列表格式显示角色。
实验室故事
该实验室基于花旗自行车的分析团队,花旗自行车是美国纽约市一个真正的全市自行车共享系统。该团队希望对来自其内部交易系统的数据进行分析,以更好地了解他们的乘客以及如何最好地为他们服务。
我们将首先将来自骑手交易的结构化数据加载到 Snowflake 中。稍后,我们将使用开源的半结构化 JSON 天气数据来确定骑自行车的次数与天气之间是否存在任何相关性。.csv
准备加载数据
首先,我们准备将结构化的 Citi Bike 骑手交易数据加载到 Snowflake 中。
本部分将指导您完成以下步骤:
- 创建数据库和表。
- 创建外部存储区。
- 为数据创建文件格式。
将数据导入 Snowflake可通过多种方式将数据从多个位置导入 Snowflake,包括 COPY 命令、Snowpipe 自动摄取、外部连接器或第三方 ETL/ELT 解决方案。有关将数据导入 Snowflake 的更多信息,请参阅 Snowflake 文档。在本实验中,我们使用 COPY 命令和 AWS S3 存储来手动加载数据。在实际场景中,您更有可能使用自动化流程或 ETL 解决方案。
我们将使用的数据是由Citi Bike NYC提供的自行车共享数据。数据已导出并预暂存到美国东部区域的 Amazon AWS S3 存储桶中。数据包括有关旅行时间、位置、用户类型、性别、年龄等的信息。在 AWS S3 上,数据表示 61.5M 行、377 个对象和 1.9GB 压缩。
以下是 Citi Bike CSV 数据文件之一的片段: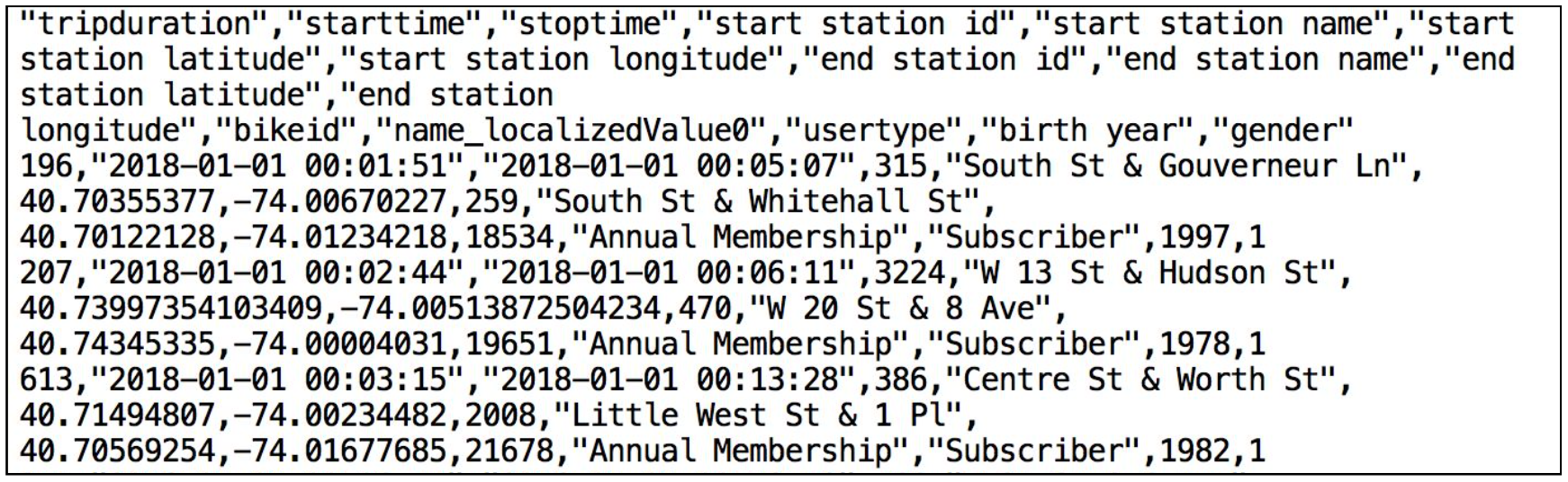 它采用逗号分隔的格式,使用单个标题行和双引号括起所有字符串值,包括标题行中的字段标题。这将在本节后面的配置中发挥作用,因为我们配置 Snowflake 表来存储此数据。
它采用逗号分隔的格式,使用单个标题行和双引号括起所有字符串值,包括标题行中的字段标题。这将在本节后面的配置中发挥作用,因为我们配置 Snowflake 表来存储此数据。
创建数据库和表
首先,让我们创建一个用于加载结构化数据的数据库。CITIBIKE
通过选择左上角的切换角色 > SYSADMIN,确保使用 SYSADMIN 角色。
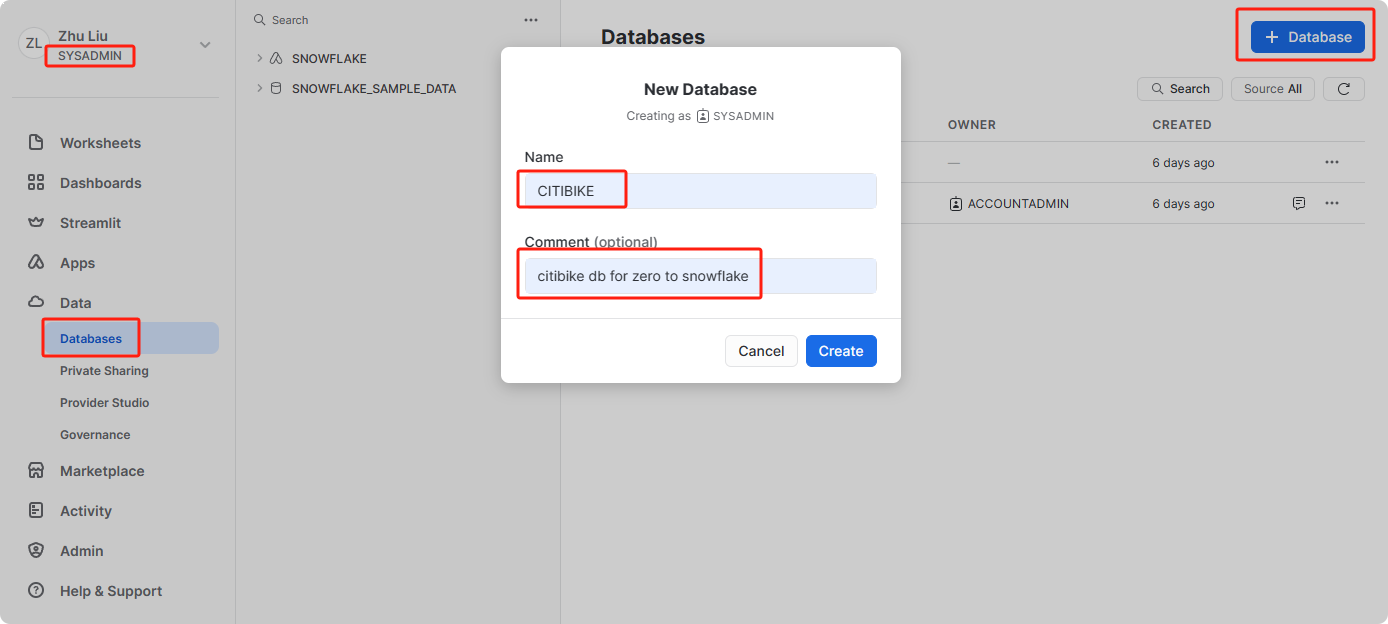
导航到数据库选项卡。单击创建,为数据库命名,然后单击“创建”。CITIBIKE
创建一个Worksheet,执行如下SQL语句,将角色和Warehouse切换成SYSADMIN 和 COMPUTE_WH1
2
3
4
5
6
7
8
9--切换到 ACCOUNTADMIN 角色
USE ROLE ACCOUNTADMIN;
--将 COMPUTE_WH 权限授权给 SYSADMIN
GRANT OPERATE ON WAREHOUSE COMPUTE_WH TO ROLE SYSADMIN;
GRANT USAGE ON WAREHOUSE COMPUTE_WH TO ROLE SYSADMIN;
--将管理warehouse权限授权给SYSADMIN
GRANT MANAGE WAREHOUSES ON ACCOUNT TO ROLE SYSADMIN;
--切换到 SYSADMIN 角色
USE ROLE SYSADMIN; 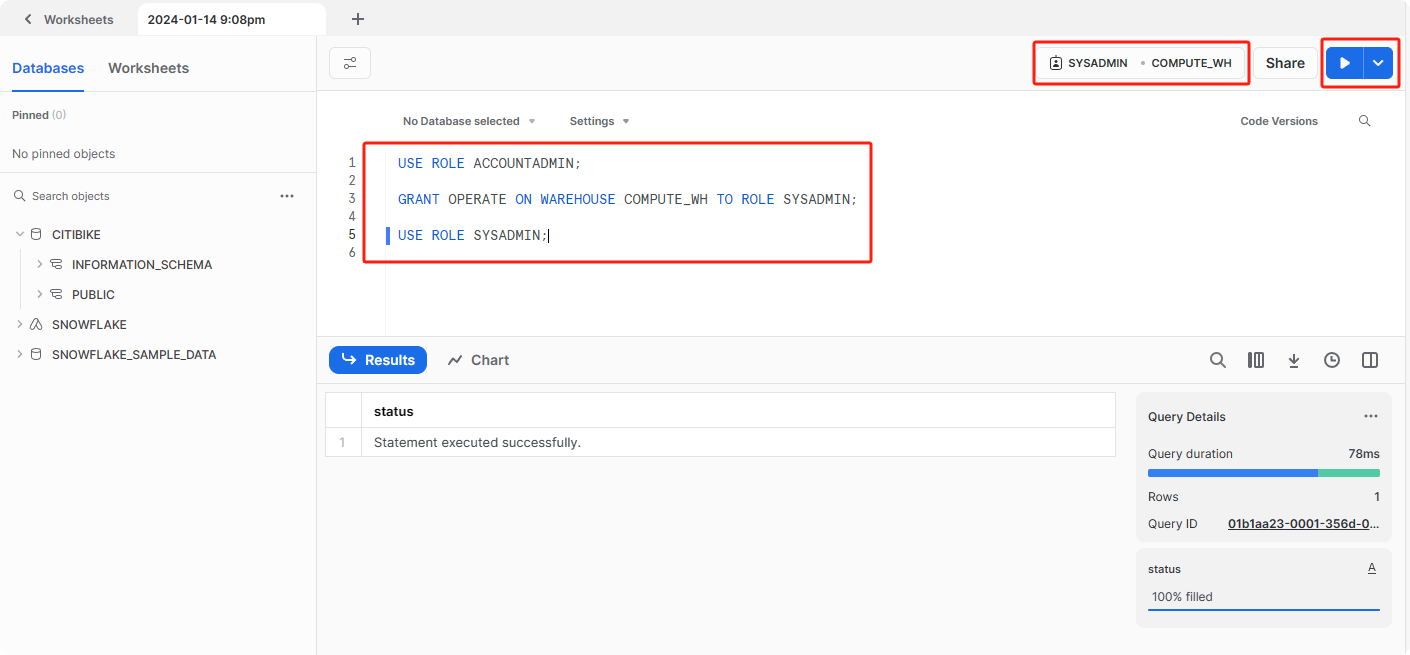
将Databases和Schemas选成刚刚创建好的CITIBIKE PUBLIC
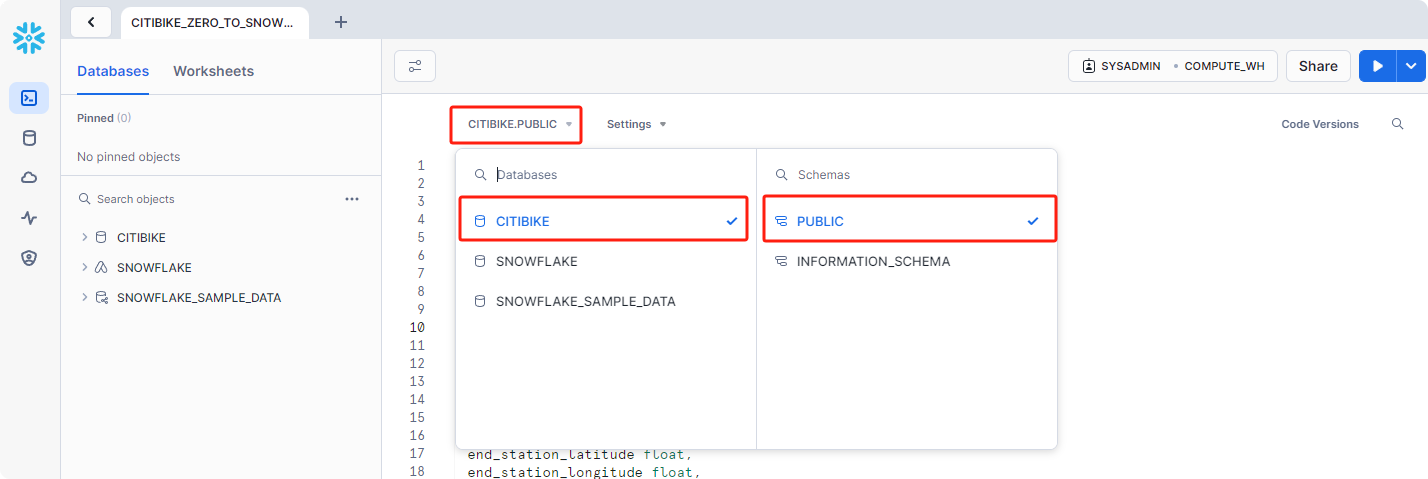
接下来,我们创建一个用于加载逗号分隔数据的表。我们不使用 UI,而是使用工作表来运行创建表的 DDL。将以下 SQL 文本复制到工作表中:TRIPS1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20--创建表trips
create or replace table trips
(
tripduration integer,
starttime timestamp,
stoptime timestamp,
start_station_id integer,
start_station_name string,
start_station_latitude float,
start_station_longitude float,
end_station_id integer,
end_station_name string,
end_station_latitude float,
end_station_longitude float,
bikeid integer,
membership_type string,
usertype string,
birth_year integer,
gender integer
);
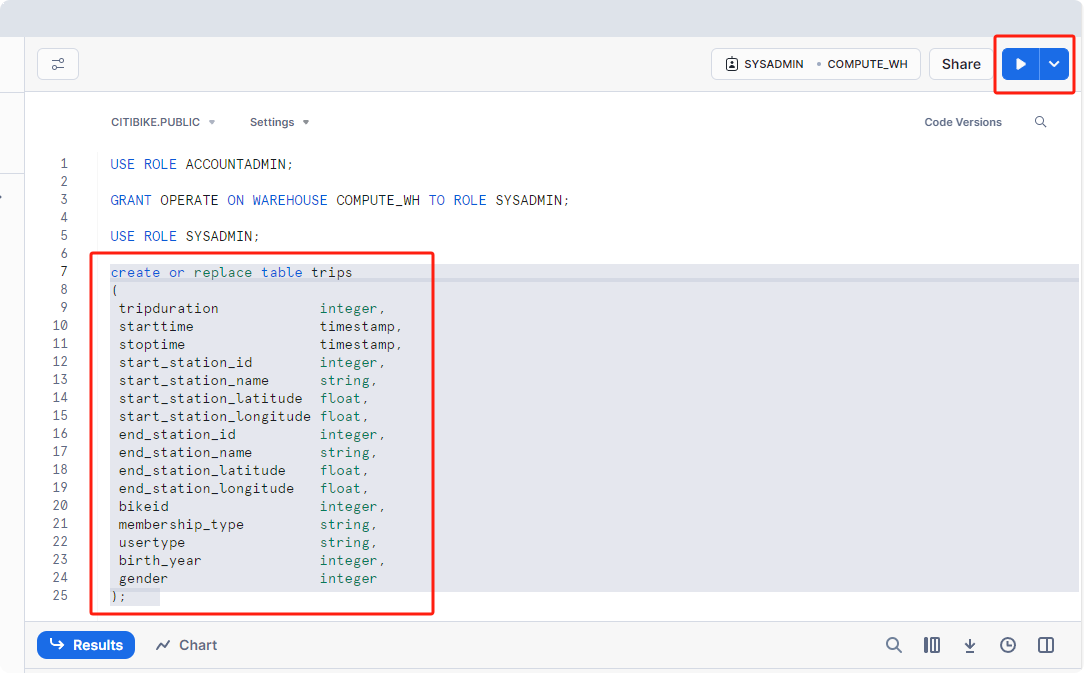
SQL 命令可以通过 UI、工作表选项卡、使用 SnowSQL 命令行工具、通过 ODBC/JDBC 选择的 SQL 编辑器或通过我们的其他连接器(Python、Spark 等)执行。如前所述,为了节省时间,我们通过工作表中执行的预先编写的 SQL 来执行本实验中的大部分操作,而不是使用 UI。
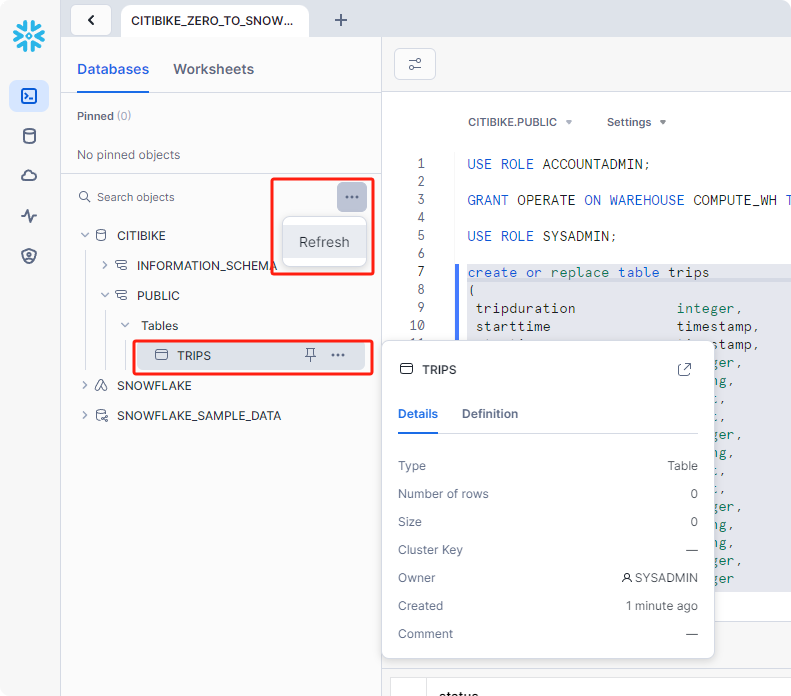
创建完成后,可以通过点击左侧Refresh,即可查看到新创建的表 CITIBIKE>PUBLIC>Tables>TRIPS
创建外部Stage
我们正在处理结构化的逗号分隔数据,这些数据已暂存于公有的外部 S3 存储桶中。在使用此数据之前,我们首先需要创建一个 Stage 来指定外部存储桶的位置。
在本实验中,我们使用的是 AWS-East 存储桶。为防止将来产生数据传出/传输成本,您应从与您的 Snowflake 帐户相同的云提供商和区域中选择暂存位置。
在数据库选项卡中,单击CITIBIKE和PUBLIC。单击 Create (创建) 按钮,然后单击 Stage > Amazon S3。
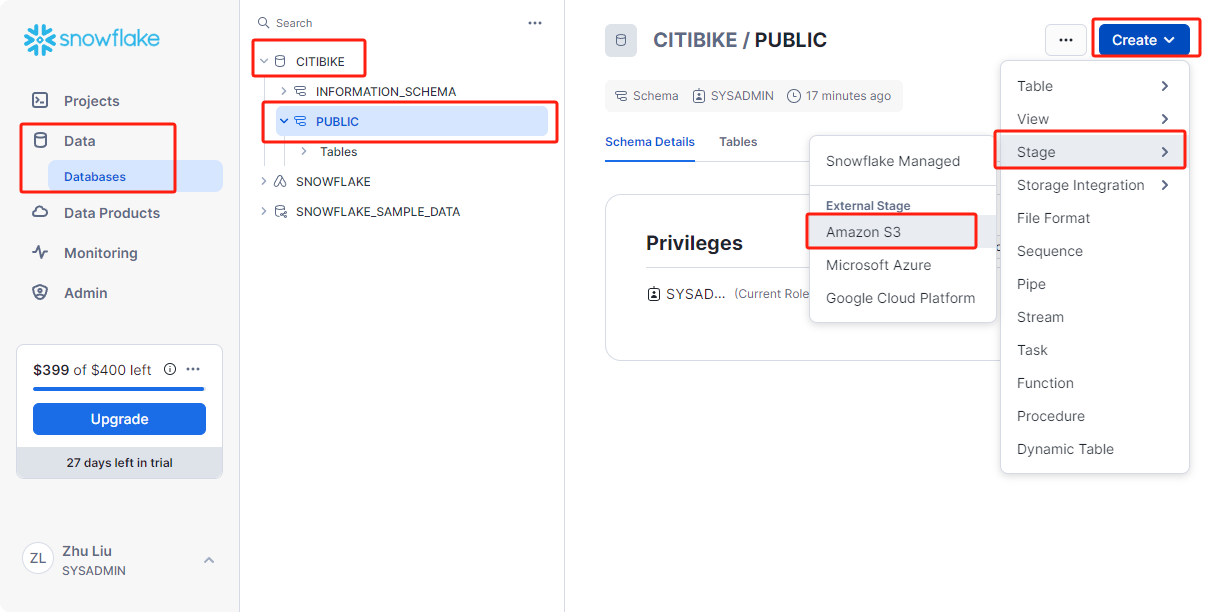
在弹出来的页面中填入citibike_trips 和 s3://snowflake-workshop-lab/citibike-trips-csv/
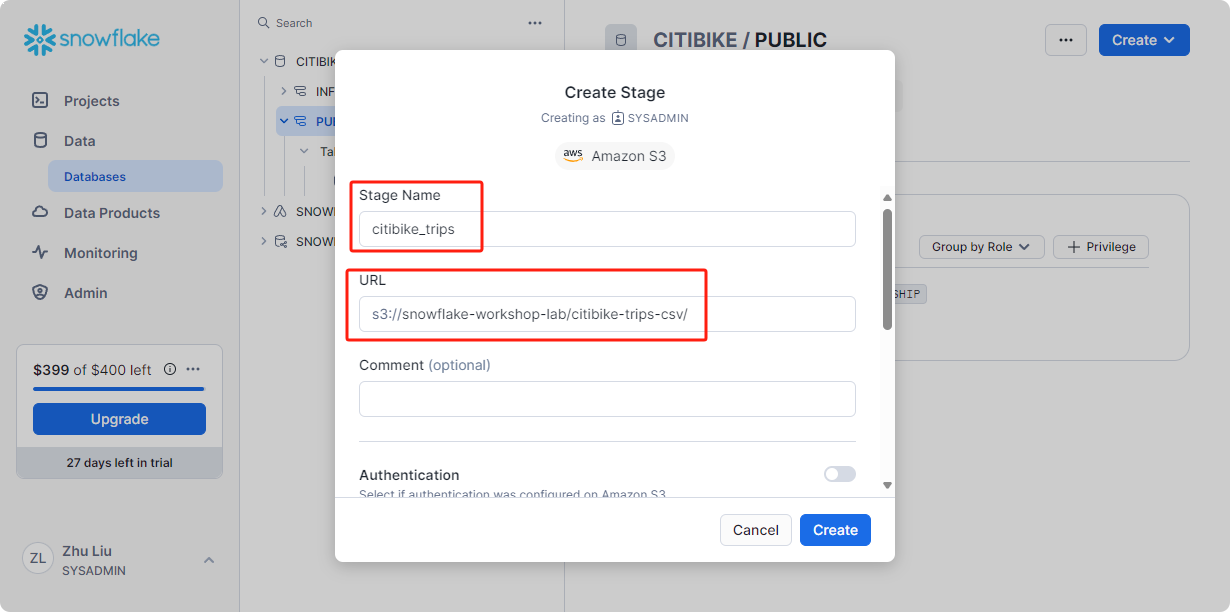
也可以在工作表中执行SQL1
2
3create stage citibike_trips
url = 's3://snowflake-workshop-lab/citibike-trips-csv/';
--credentials = (aws_secret_key = '<key>' aws_key_id = '<id>')
此练习的 S3 存储桶是公有的,因此您可以将语句中的凭证选项留空。在实际场景中,用于外部阶段的存储桶可能需要关键信息。
在工作表中执行如下SQL,在底部窗格中的结果中,应看到阶段中的文件列表:
1 | list @citibike_trips; |
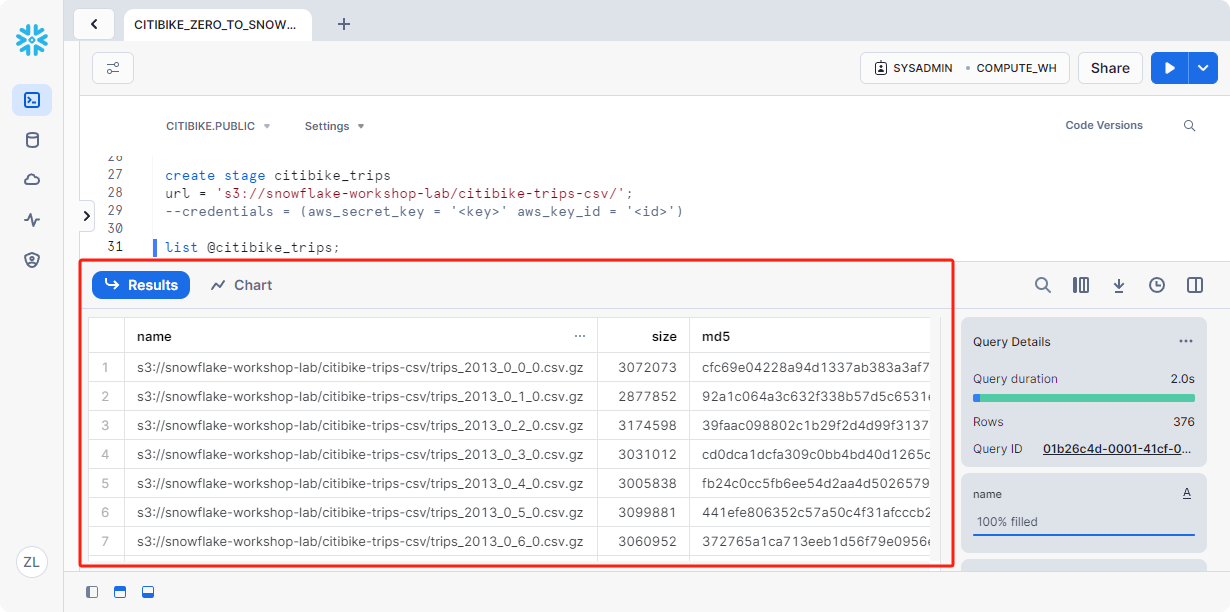
创建file format
在将数据加载到 Snowflake 中之前,我们必须创建与数据结构匹配的文件格式。
在工作表中,执行下方SQL来创建文件file format
1 | --create file format |
通过执行以下命令,验证是否已使用正确的设置创建文件格式:
1 | --verify file format is created |
加载数据
现在,我们可以运行 COPY 命令将数据加载到我们之前创建的表中。TRIPS
在工作表中执行以下语句,将暂存数据加载到表中。
1 | use warehouse COMPUTE_WH; |
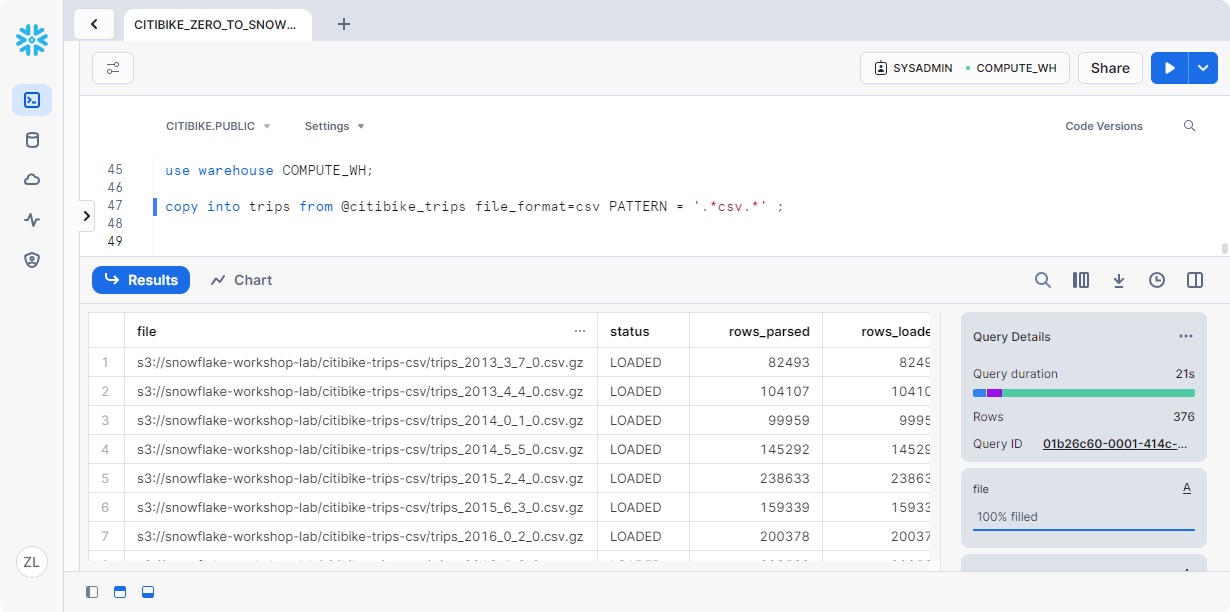
在结果窗格中,应看到已加载的每个文件的状态。加载完成后,在右下角的“查询详细信息”窗格中,可以滚动浏览最后执行的语句的各种状态、错误统计信息和可视化效果:
可以在Query Hisory中查看查询执行的步骤、查询详细信息、最昂贵的节点和其他统计信息。
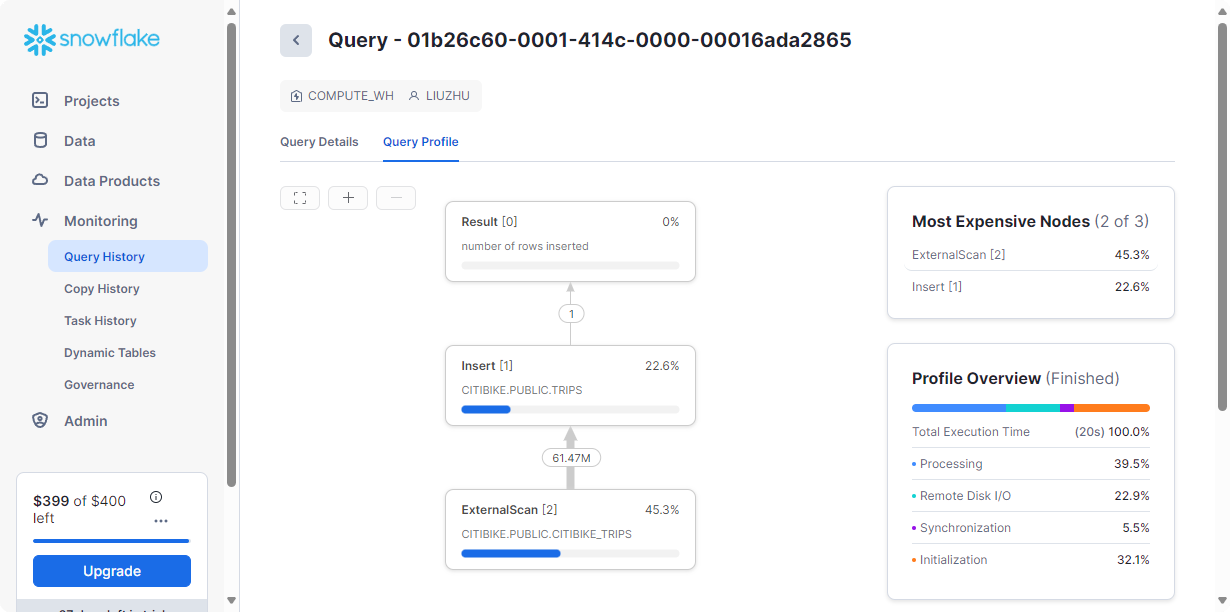
现在,让我们使用更大的仓库重新加载表,以查看额外的计算资源对加载时间的影响。TRIPS
返回到工作表,并使用 TRUNCATE TABLE 命令清除表中的所有数据和元数据:
1 | truncate table trips; |
通过运行以下命令验证表是否为空:
1 | --verify table is clear |
将仓库大小更改为使用以下 ALTER WAREHOUSE:large
1 | --change warehouse size from small to large (4x) |
使用以下 SHOW WAREHOUSES 验证更改:
1 | --load data with large warehouse |
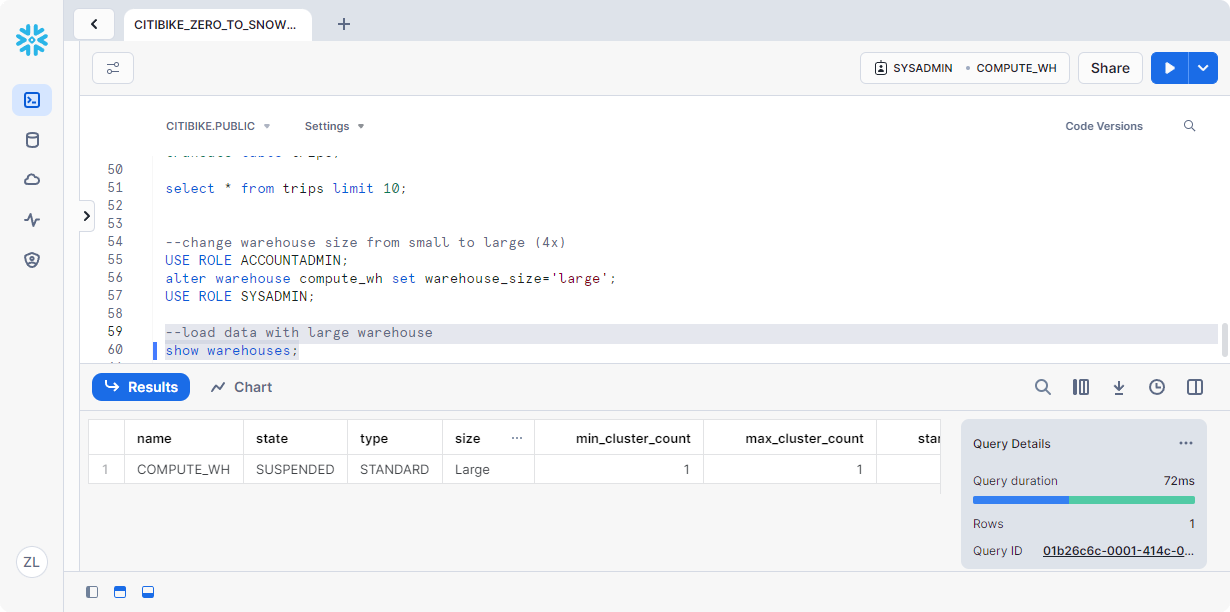
执行与之前相同的 COPY INTO 语句以再次加载相同的数据:
1 | copy into trips from @citibike_trips |

比较两个 COPY INTO 命令的时间。使用Large的速度明显更快。
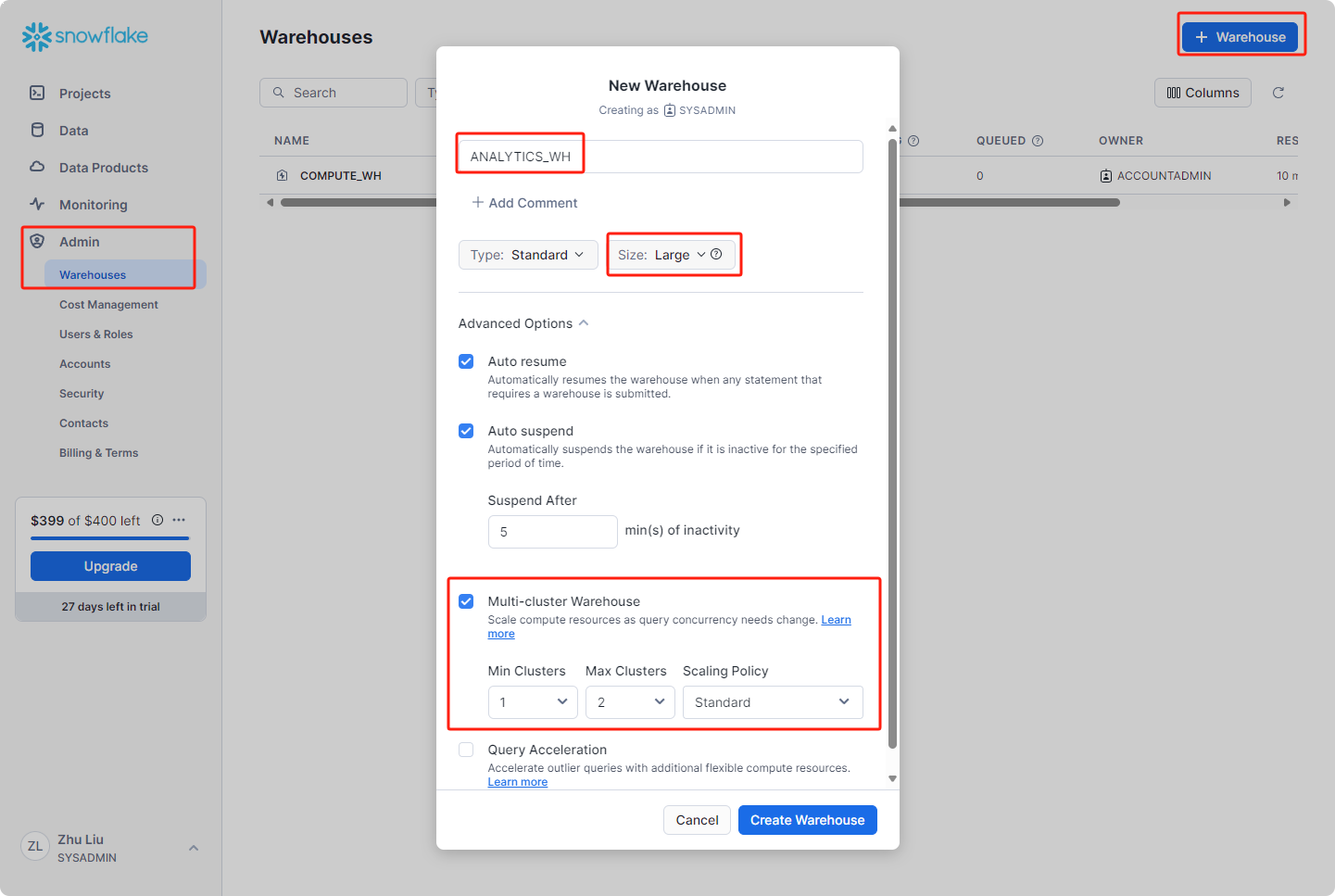
为数据分析创建新仓库ANALYTICS_WH
导航到Admin>Warehouses选项卡,单击右上角+ Warehouse,然后将新仓库命名为ANALYTICS_WH,并将大小设置为Large,启用多集群仓库,点击创建仓库
使用 Queries, Results Cache, & Cloning
在前面的练习中,我们使用 Snowflake 的 COPY 批量加载程序命令和虚拟仓库将数据加载到两个表中。现在,我们将扮演Citi Bike的分析用户的角色,他们需要使用工作表和第二个仓库查询这些表中的数据。COMPUTE_WH``ANALYTICS_WH
在实际公司中,分析用户的角色可能与 SYSADMIN 不同。为了简化实验,我们将在本部分中保留 SYSADMIN 角色。此外,查询通常使用 Tableau、Looker、PowerBI 等商业智能产品完成。对于更高级的分析,Datarobot、Dataiku、AWS Sagemaker 等数据科学工具可以查询 Snowflake。任何利用 JDBC/ODBC、Spark、Python 或任何其他受支持的编程接口的技术都可以对 Snowflake 中的数据运行分析。为了简化此实验,所有查询都通过 Snowflake 工作表执行。
执行一些查询
回到工作表,更改仓库以使用您在刚刚创建的新仓库ANALYTICS_WH
1 | use warehouse analytics_wh; |
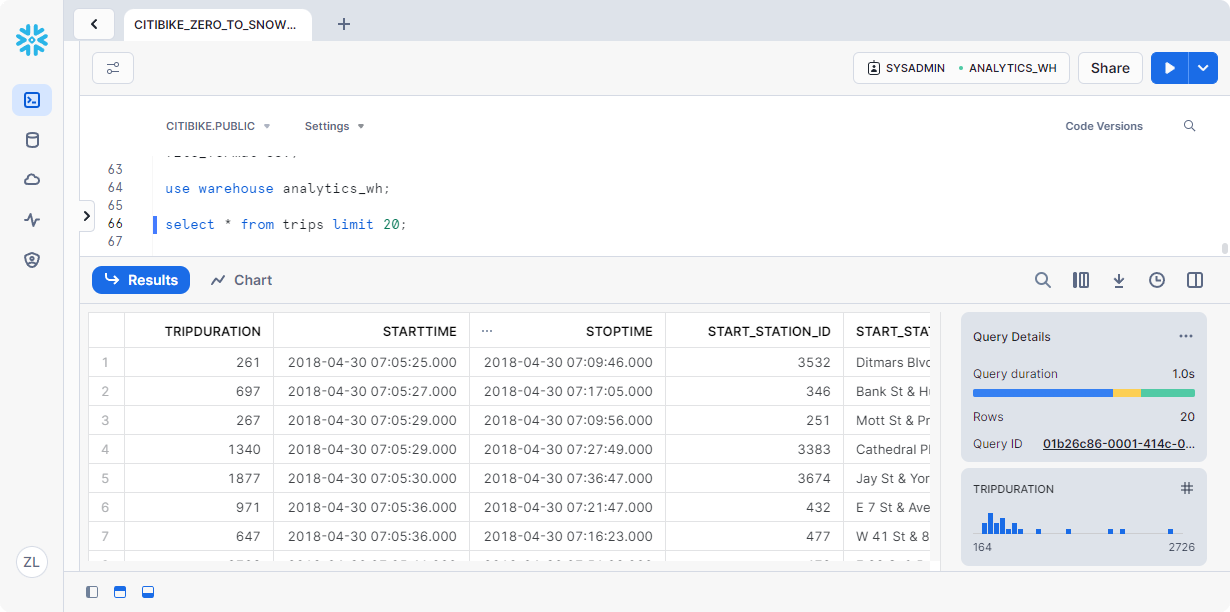
运行以下查询以查看数据示例:1
select * from trips limit 20;
现在,让我们看一下花旗自行车使用情况。在工作表中运行下面的查询。对于每小时,它显示行程数、平均行程持续时间和平均行程距离。
1 | select date_trunc('hour', starttime) as "date", |
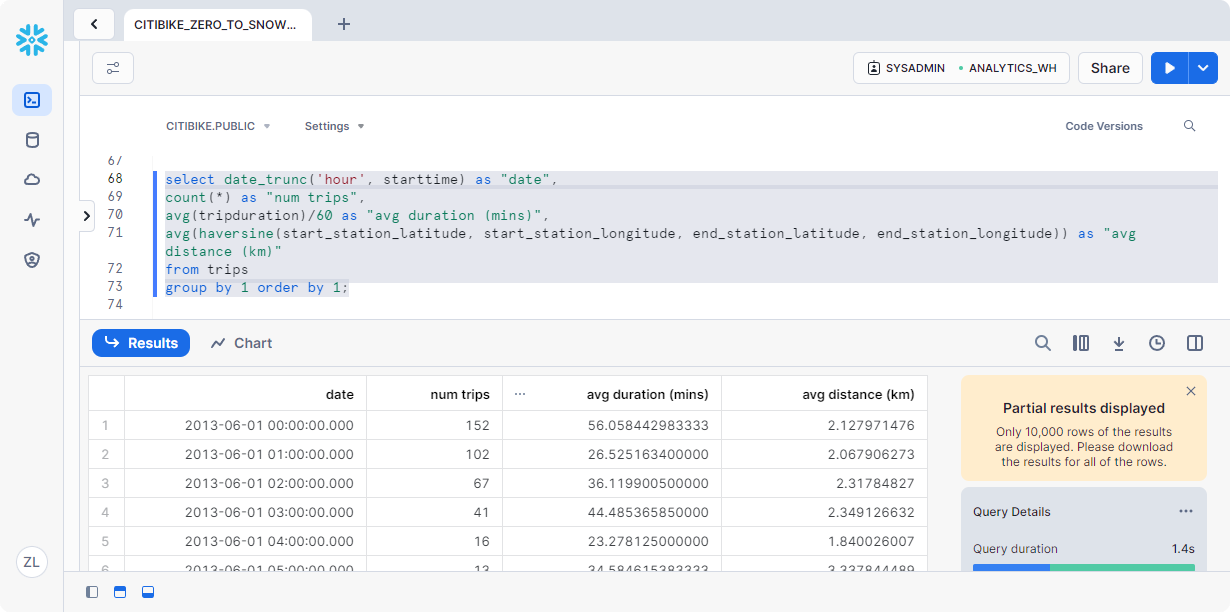
使用结果缓存
Snowflake 有一个结果缓存,用于保存过去 24 小时内执行的每个查询的结果。这些查询在仓库中可用,因此,如果基础数据未更改,则返回给一个用户的查询结果可供系统上执行相同查询的任何其他用户使用。这些重复查询不仅返回速度极快,而且不使用计算积分。
让我们通过再次运行完全相同的查询来查看结果缓存的运行情况。
1 | select date_trunc('hour', starttime) as "date", |
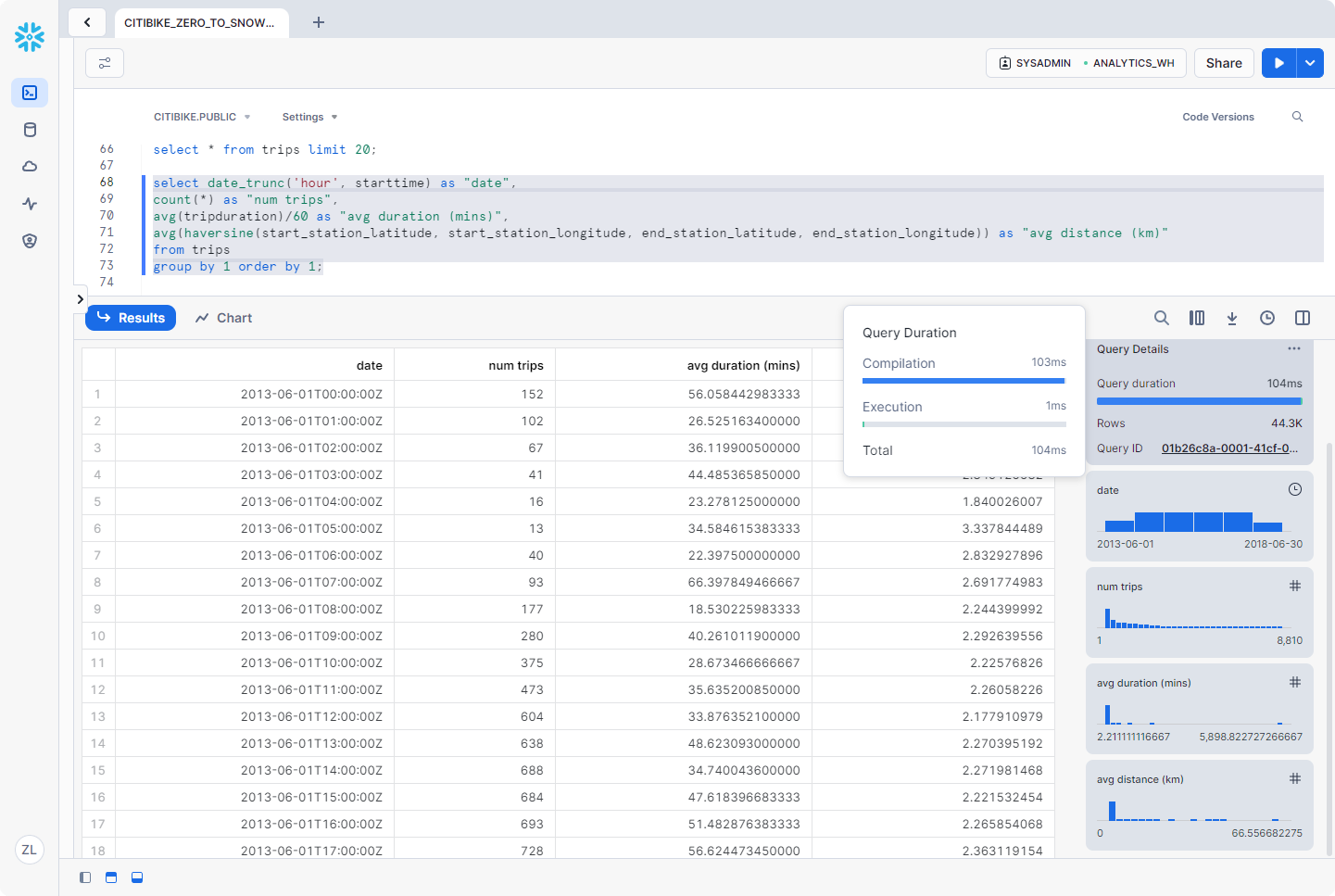
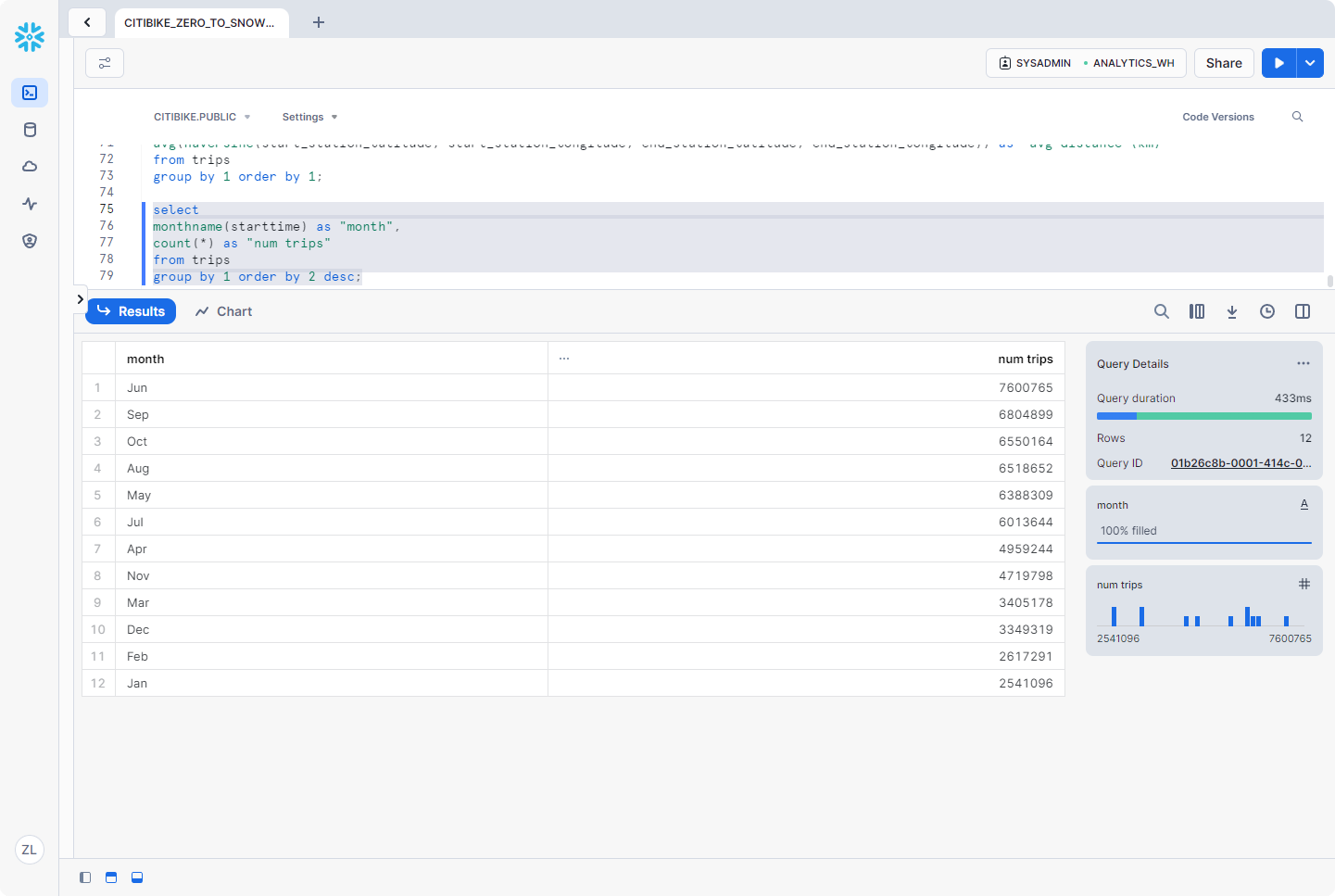
执行另一个查询
接下来,让我们运行以下查询,看看哪些月份最忙:
1 | select |
克隆表
Snowflake 允许您在几秒钟内创建表、架构和数据库的克隆,也称为“零拷贝克隆”。创建克隆时,Snowflake 会拍摄源对象中存在的数据的快照,并将其提供给克隆对象。克隆的对象是可写的,并且独立于克隆源。因此,对源对象或克隆对象所做的更改不包括在另一个对象中。
零拷贝克隆的一个常见用例是克隆生产环境,供开发和测试团队用于测试和实验,而不会对生产环境产生不利影响,也无需设置和管理两个单独的环境。
零拷贝克隆的一大好处是不会复制基础数据。只有元数据和指向基础数据的指针会更改。因此,克隆是“零拷贝”,克隆数据时存储要求不会翻倍。大多数数据仓库无法做到这一点,但对于 Snowflake 来说,这很容易!
在工作表中运行以下命令以创建表trips的克隆表trips_dev
1 | create table trips_dev clone trips; |
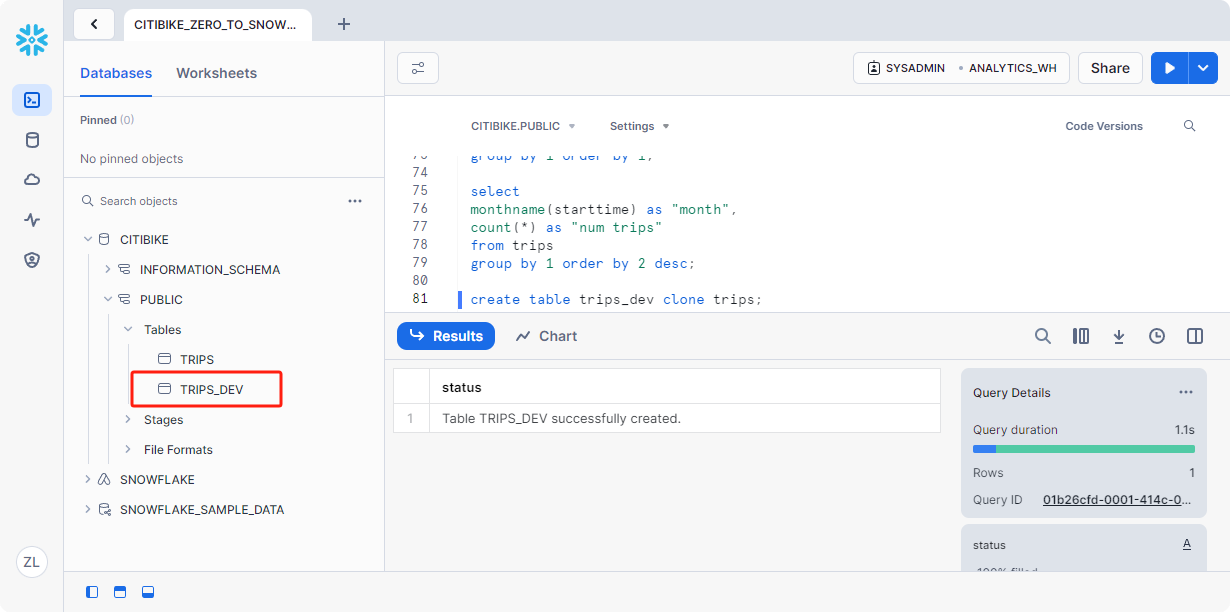
单击左窗格中的三个点 ···,然后选择刷新。现在可以对此表执行任何想要的操作,包括更新或删除它,而不会影响该表或任何其他对象。
使用半结构化数据,视图,和连接
本部分需要加载其他数据,因此,在介绍加载半结构化数据的同时,对数据加载进行了回顾。
回到实验室的例子,Citi Bike 分析团队希望确定天气如何影响骑行计数。为此,在本节中,我们将:
- 以半结构化 JSON 格式加载天气数据,保存在公有 S3 存储桶中。
- 创建视图并使用 SQL 点表示法查询 JSON 数据。
- 运行一个查询,将 JSON 数据联接到以前加载
TRIPS的数据。 - 分析天气和乘车次数数据以确定它们之间的关系。
JSON数据由MeteoStat提供的天气信息组成,详细介绍了2016-07-05至2019-06-25期间纽约市的历史状况。它还在 AWS S3 上暂存,其中数据由 75k 行、36 个对象和 1.1MB 压缩组成。如果在文本编辑器中查看,GZ 文件中的原始 JSON 如下所示:

Snowflake 可以轻松加载和查询 JSON、Parquet 或 Avro 等半结构化数据,而无需转换。这是 Snowflake 的一个关键功能,因为如今生成的越来越多的与业务相关的数据是半结构化的,许多传统数据仓库无法轻松加载和查询此类数据。Snowflake让一切变得简单!
为数据创建新的数据库和表
首先,在工作表中,让我们创建一个用于存储半结构化 JSON 数据的数据库WEATHER
1 | create database weather; |
请记住,您需要单独执行每个命令。但是,您可以通过选中所有命令,然后单击右上角
▶按钮(或使用键盘快捷键Ctrl + Enter)来按顺序执行它们。
接下来,让我们创建一个用于加载 JSON 数据的表json_weather_data。在工作表中,执行以下 CREATE TABLE 命令:
1 | create table json_weather_data (v variant); |
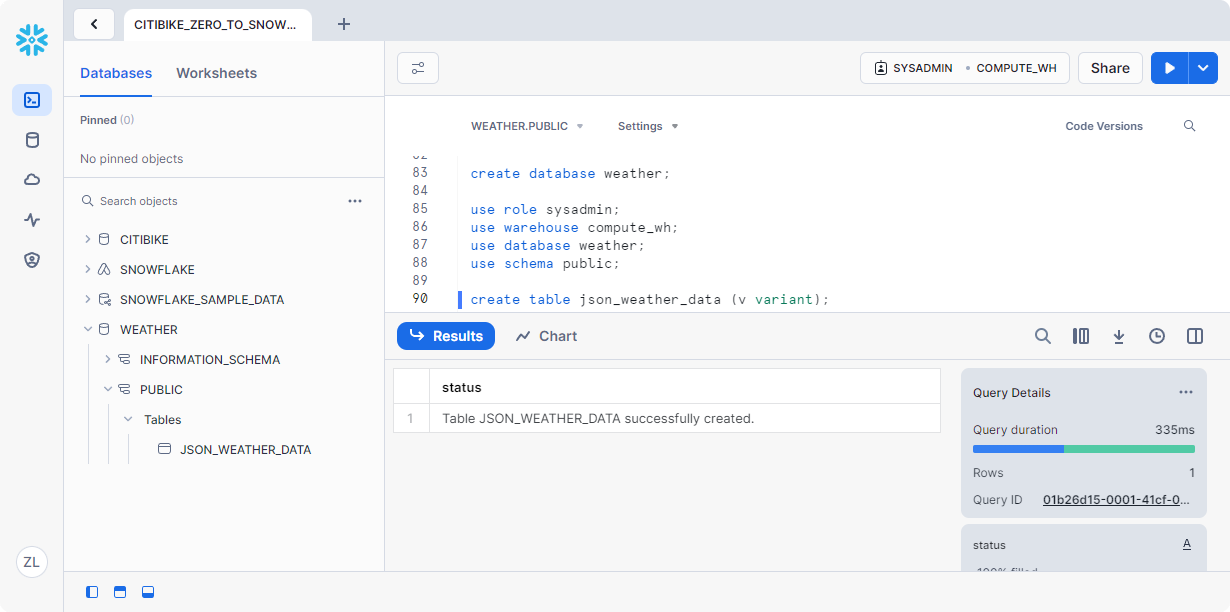
VARIANT 数据类型允许 Snowflake 读取半结构化数据,而无需预定义架构。
创建另一个外部stage
在工作表中,使用以下命令创建一个stage,该stage指向 AWS S3 上存储半结构化 JSON 数据的存储桶:
1 | create stage nyc_weather |
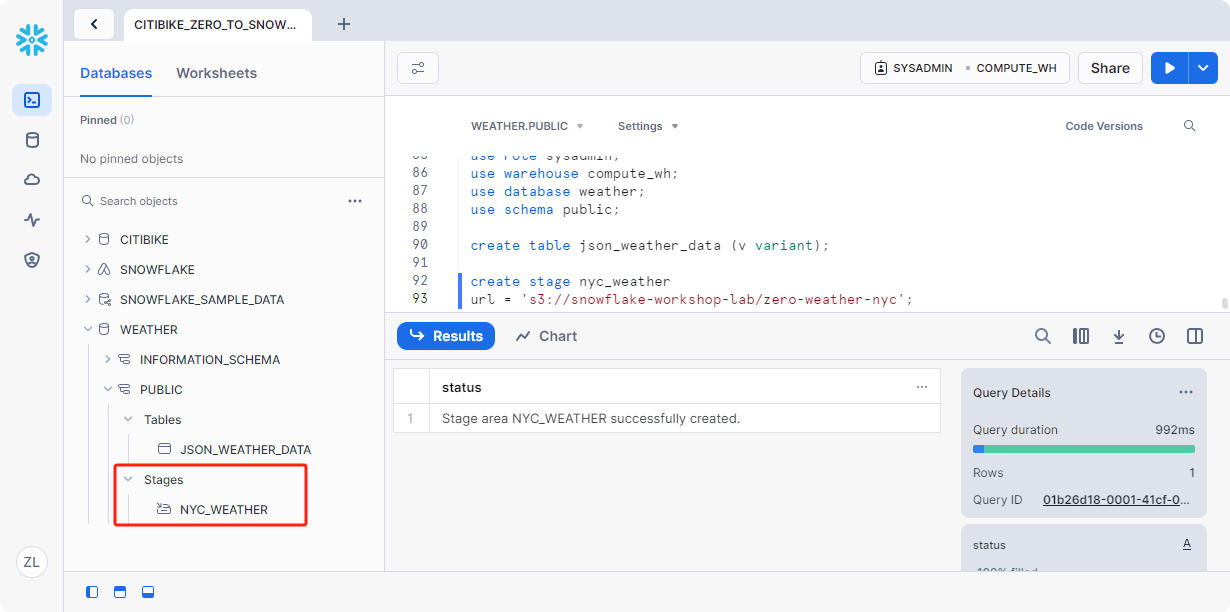
执行以下 LIST 命令以显示文件列表nyc_weather
1 | list @nyc_weather; |
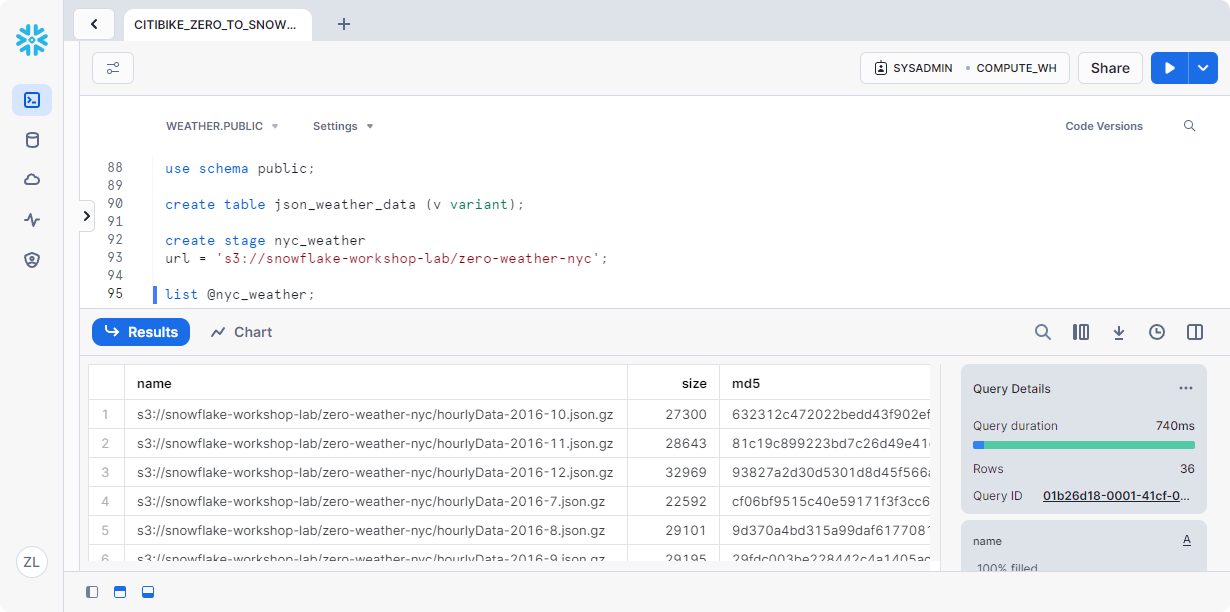
在结果窗格中,您应看到来自 S3 的文件列表.gz
加载并验证半结构化数据
在本节中,我们将使用仓库将数据从 S3 存储桶加载到我们之前创建的表中JSON_WEATHER_DATA
在工作表中,执行下面的 COPY 命令以加载数据:
1 | copy into json_weather_data |
请注意,您可以在命令中内联指定对象。在上一节中,我们以 CSV 格式加载结构化数据,我们必须定义一种文件格式来支持 CSV 结构。由于此处的 JSON 数据格式正确,因此我们能够简单地指定 JSON 类型并使用所有默认设置
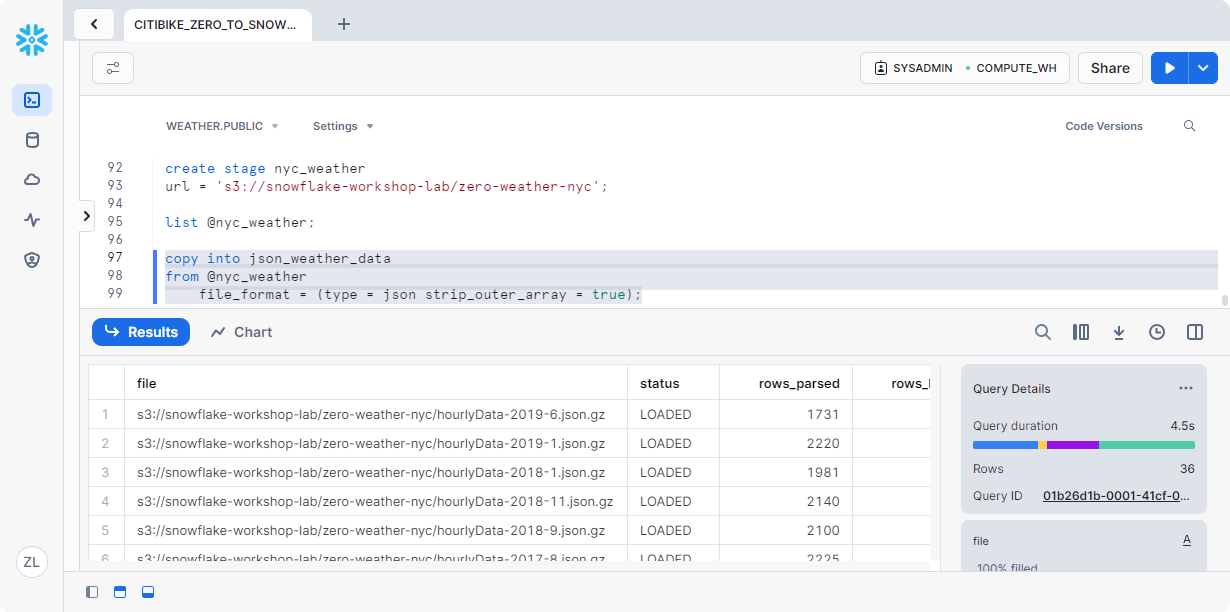
现在,让我们看一下加载的数据:
1 | select * from json_weather_data limit 10; |
单击任意一行在右侧面板中显示格式化的 JSON:
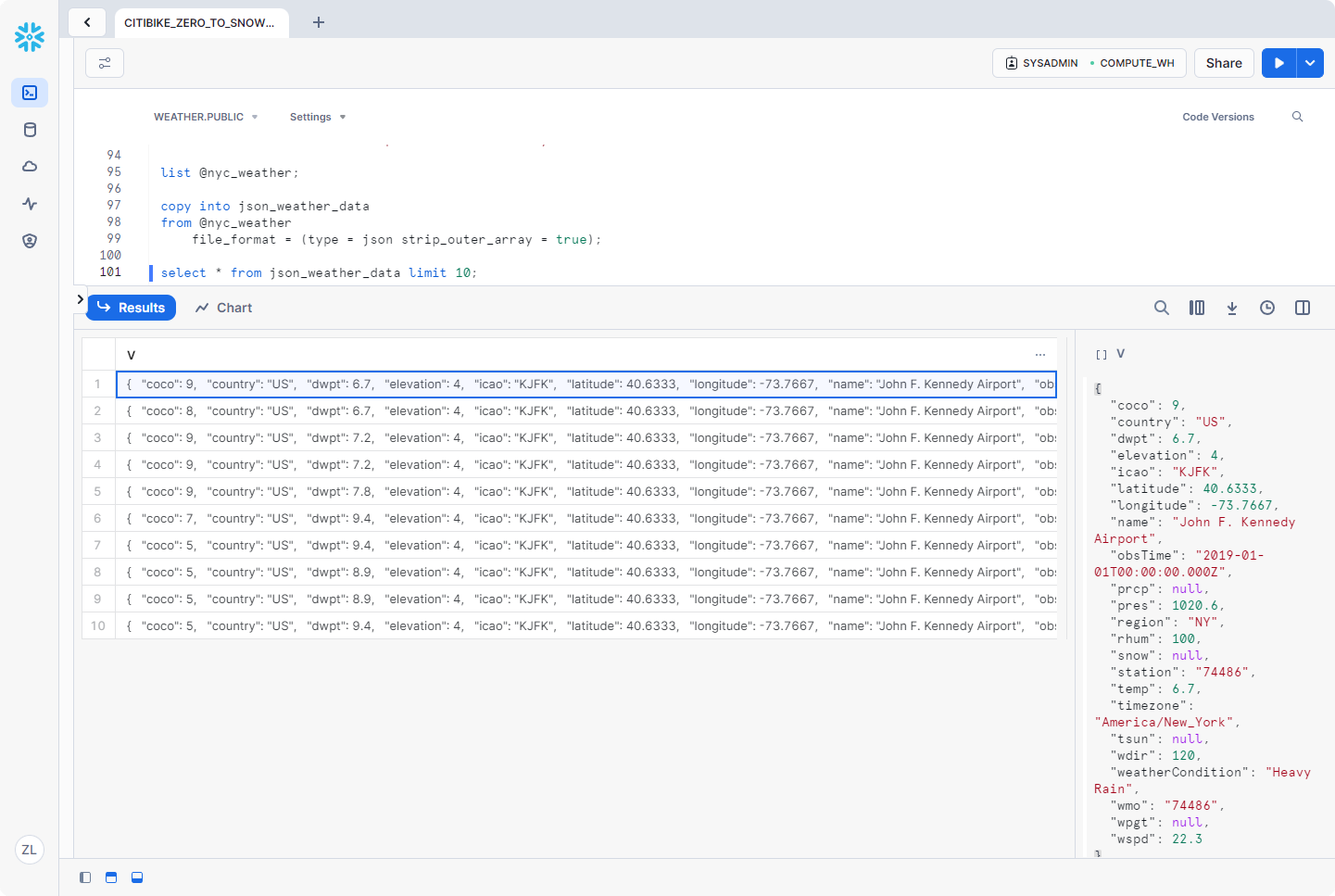
创建视图并查询半结构化数据
接下来,让我们看看 Snowflake 如何允许我们创建视图并直接使用 SQL 查询 JSON 数据。
视图允许像访问表一样访问查询结果。视图可以帮助以更清晰的方式向最终用户呈现数据,限制最终用户可以在源表中查看的内容,并编写更多的模块化 SQL。Snowflake 还支持实例化视图,其中存储查询结果就像存储结果一样。这允许更快的访问,但需要存储空间。如果您使用的是 Snowflake Enterprise Edition(或更高版本),则可以创建和查询实例化视图。
运行以下命令以创建半结构化 JSON 天气数据的列式视图,以便分析师更容易理解和查询。的值对应于 Newark Airport,这是整个期间有天气状况的最近车站。
1 | // create a view that will put structure onto the semi-structured data |
此命令中使用 SQL 点表示法来提取 JSON 对象层次结构中较低级别的值。这使我们能够将每个字段视为关系表中的一列
v:temp
使用以下查询验证视图:
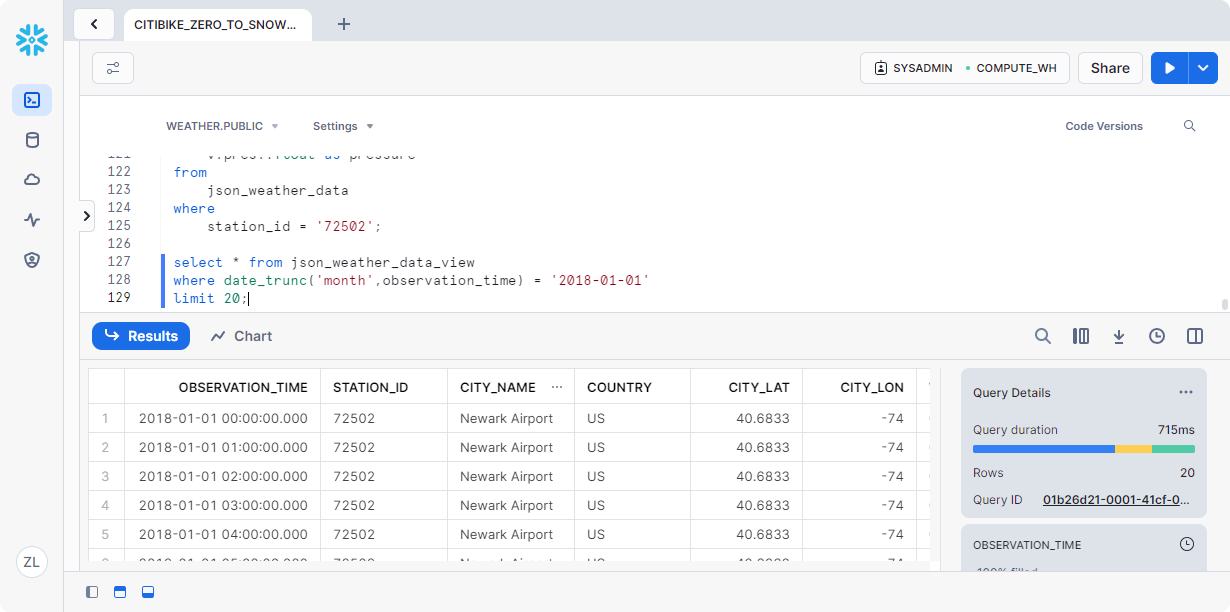
1 | select * from json_weather_data_view |
使用联接操作与数据集相关联
现在,我们将把JSON天气数据加入到我们的数据中,以回答我们最初的问题,即天气如何影响乘车次数。
因为我们仍在工作表中,所以数据库仍在使用中。因此,您必须通过提供表的数据库和架构名称来完全限定对表的引用。
WEATHERTRIPS
1 | select weather_conditions as conditions |
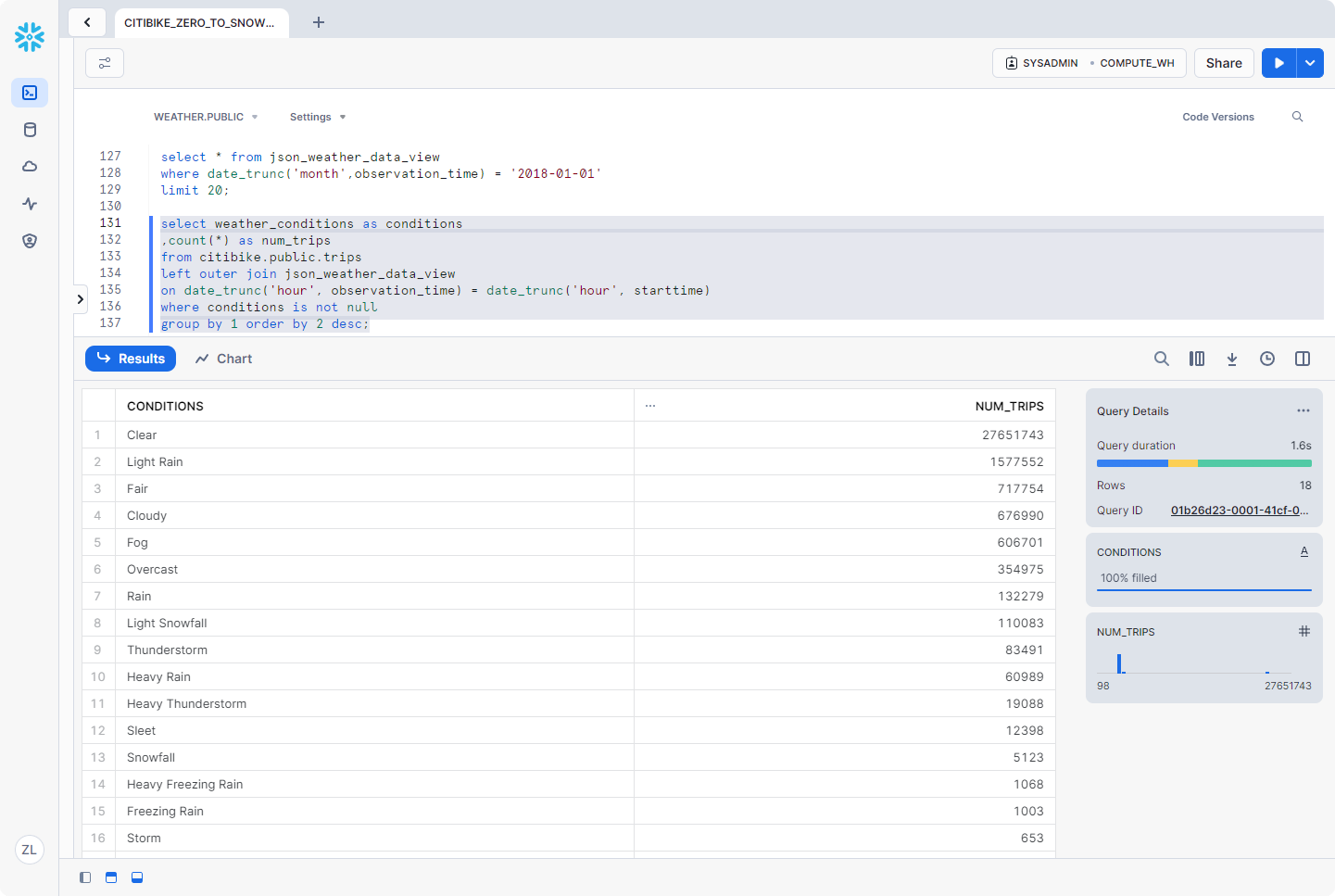
最初的目标是通过分析乘客数量和天气数据来确定骑自行车的次数与天气之间是否存在任何相关性。根据上面的结果,我们有一个明确的答案。可以想象,天气好的时候,出行次数要多得多!
使用Time Travel
Snowflake 强大的Time Travel功能可以在一段时间内的任何时间点访问历史数据以及存储数据的对象。默认窗口为 24 小时,如果您使用的是 Snowflake 企业版,则最多可以增加到 90 天。大多数数据仓库无法提供此功能,但是Snowflake 使它变得简单!
还包括:
- 还原可能已删除的数据相关对象,例如表、架构和数据库。
- 复制和备份过去关键点的数据。
- 分析指定时间段内的数据使用情况和操作情况。
删除和取消删除表
首先,让我们看看如何恢复被意外或有意删除的数据对象。
在工作表中,运行以下 DROP 命令删除该表:
1 | drop table json_weather_data; |
对表运行查询:
1 | select * from json_weather_data limit 10; |
在底部的结果窗格中,应会看到错误,因为基础表已被删除:
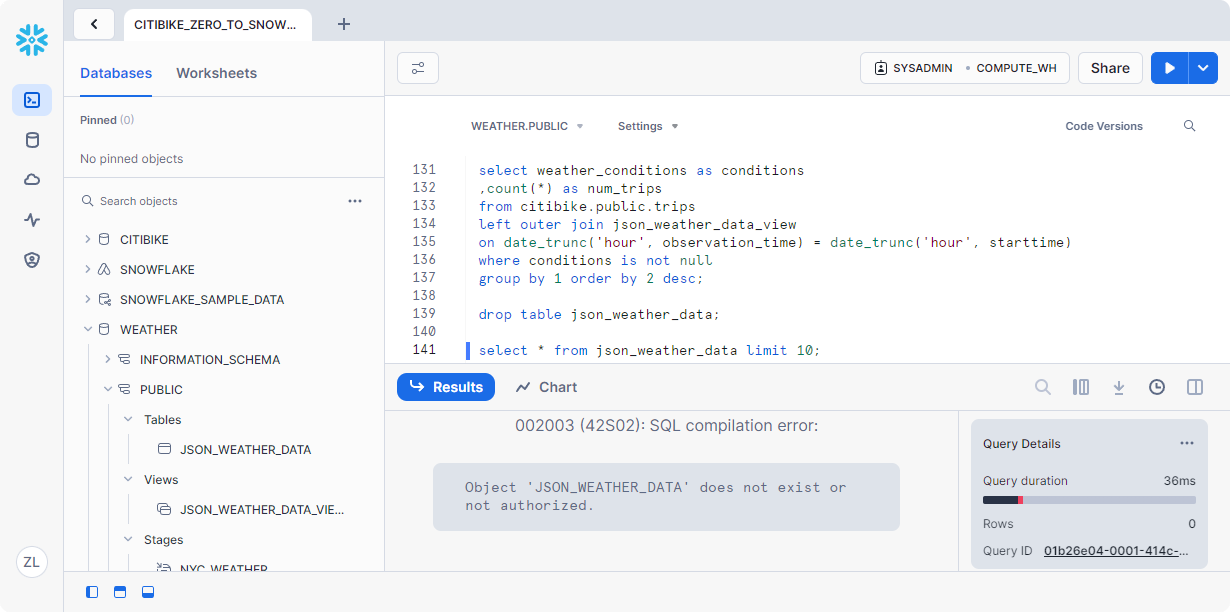
现在,还原表:
1 | undrop table json_weather_data; |
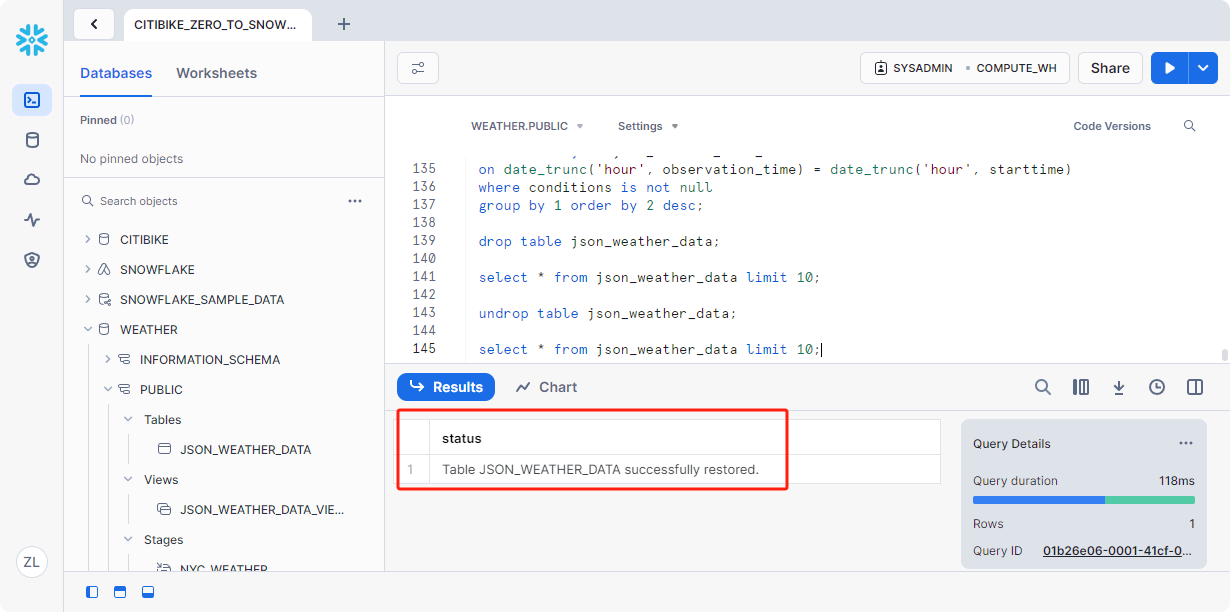
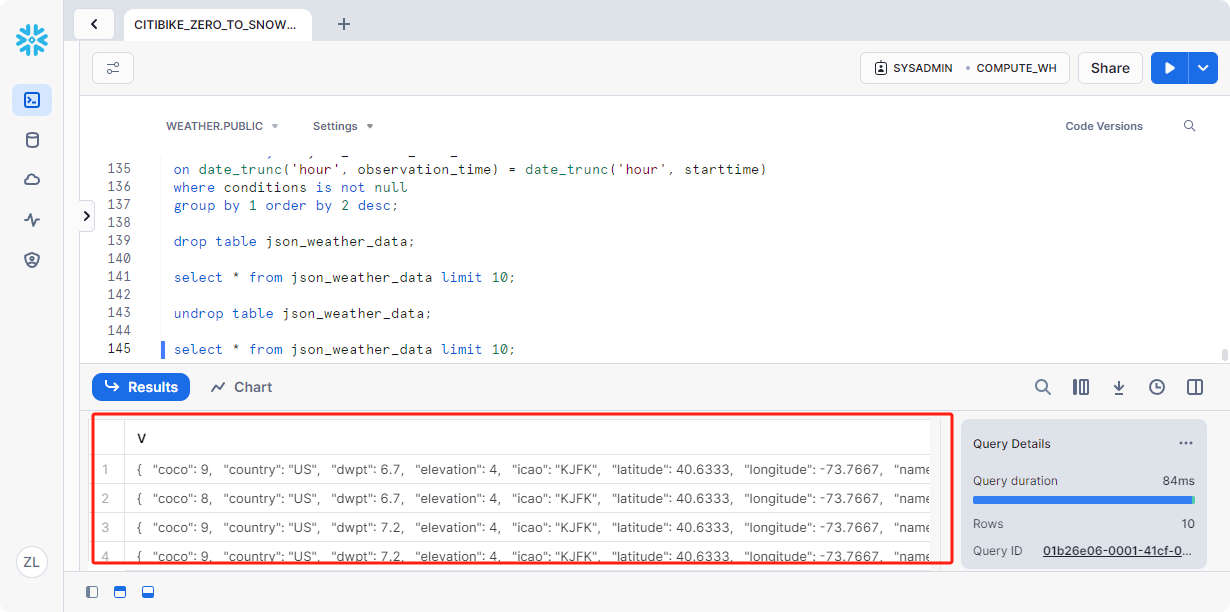
应还原json_weather_data表。通过运行以下查询进行验证:
1 | --verify table is undropped |
回滚表
让我们将数据库中的表回滚到以前的状态,以修复一个无意的 DML 错误,该错误将表中的所有站点名称替换为单词“oops”
首先,运行以下 SQL 语句将工作表切换到正确的上下文:
1 | use role sysadmin; |
运行以下命令,将表中的所有start_station_name更新为单词“oops”:
1 | update trips set start_station_name = 'oops'; |
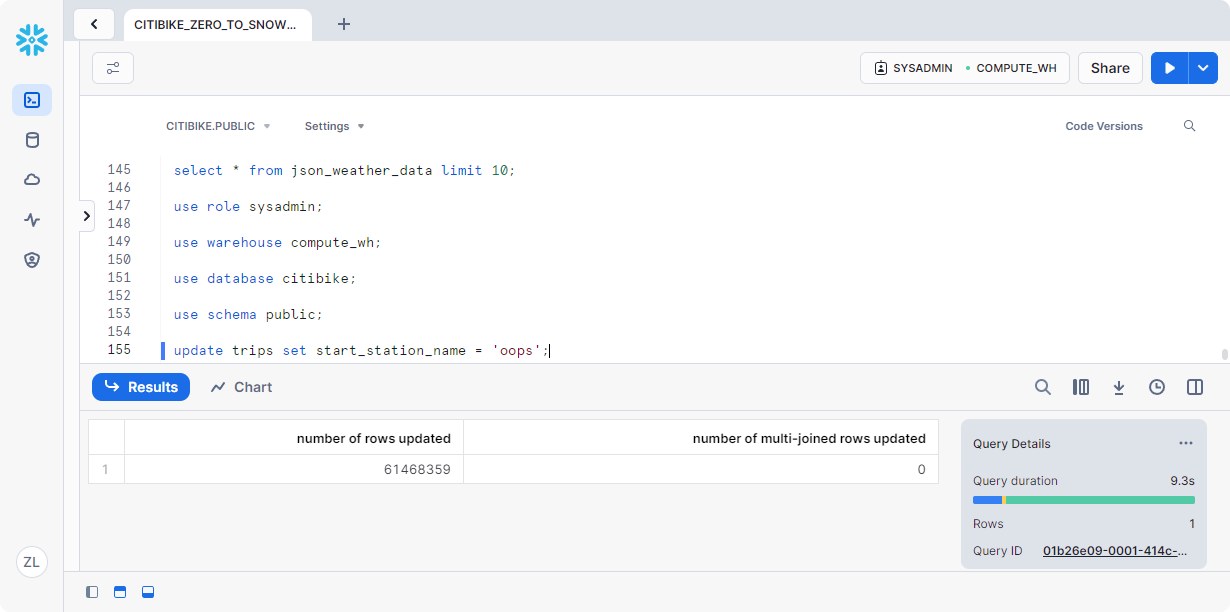
现在,运行一个查询,该查询按乘车次数返回前 20 个站点。请注意,电台名称结果仅包含一行:
1 | select |
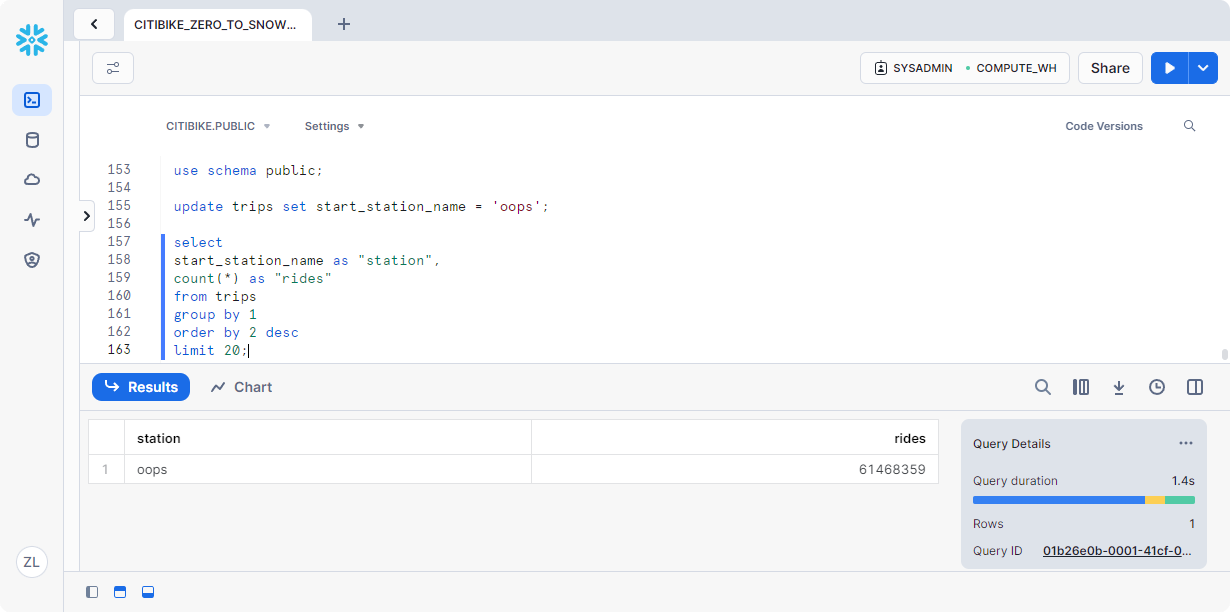
通常情况下,希望我们有一个备份。
在Snowflake 中,我们可以简单地运行一个命令来查找最后一个 UPDATE 命令的查询 ID,并将其存储在名为$QUERY_ID
1 | set query_id = |
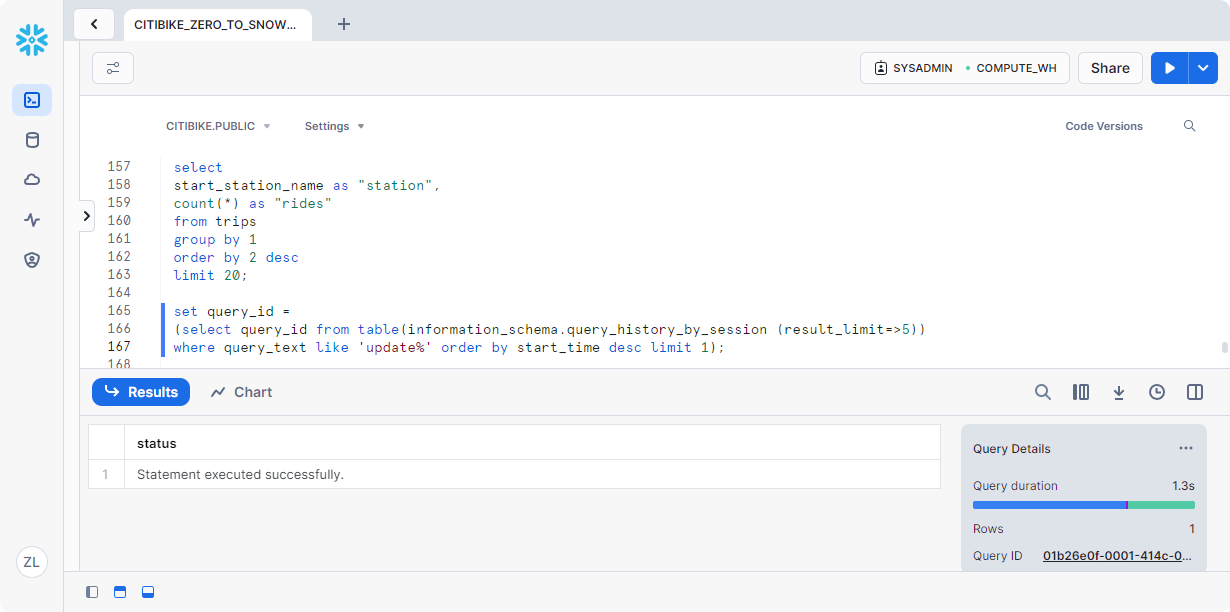
使用Time Interval重新创建表:
1 | create or replace table trips as |
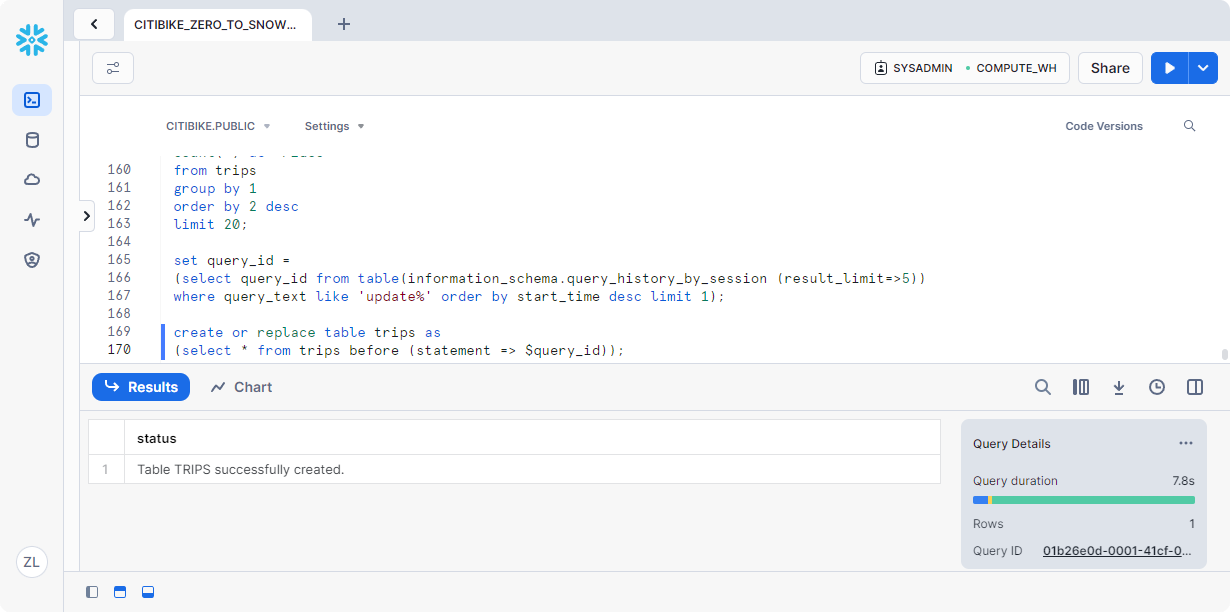
再次运行上一个查询,以验证是否已还原:
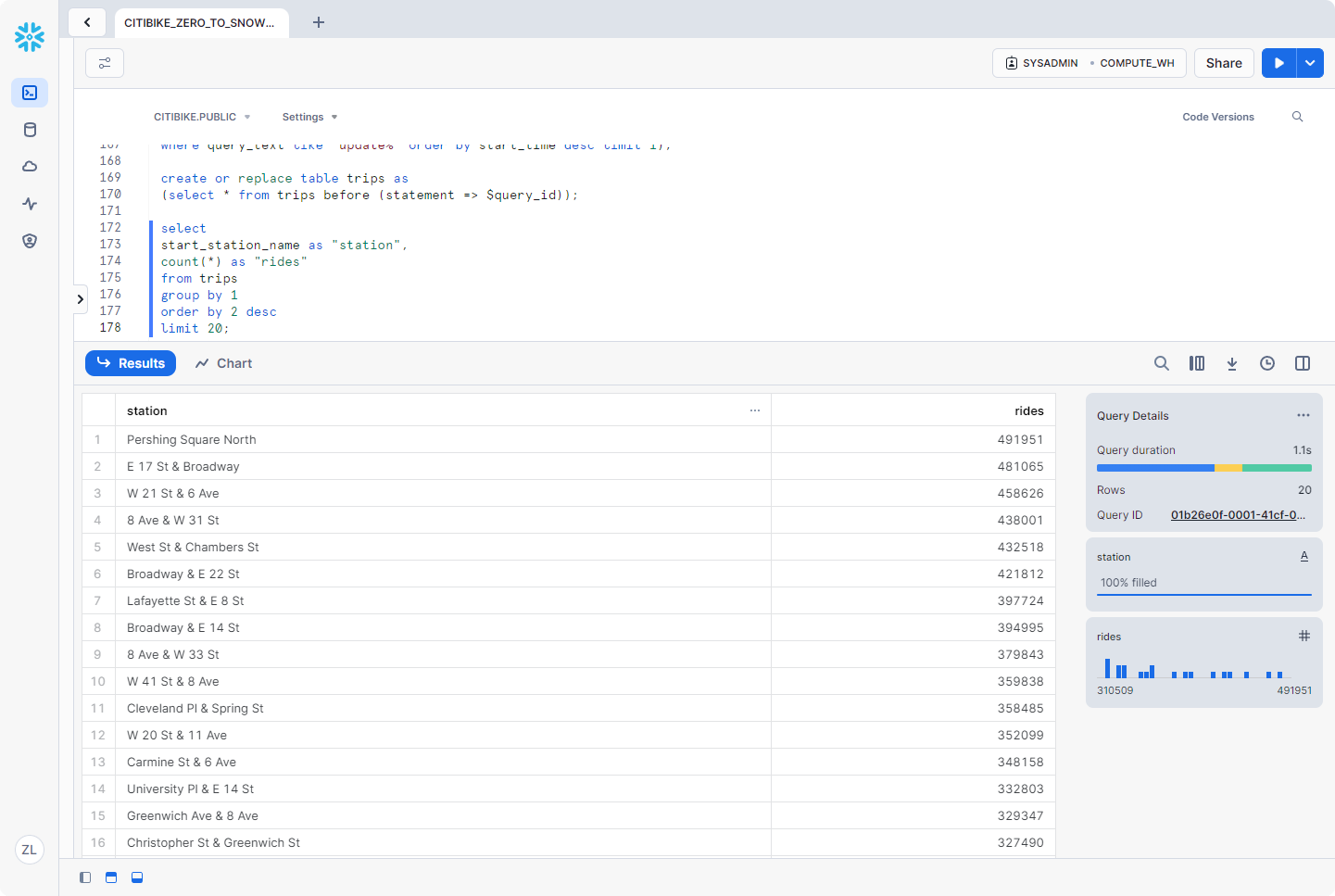
角色、帐户管理员和帐户使用情况
在本节中,我们将探讨 Snowflake 访问控制安全模型的各个方面,例如创建角色并授予其特定权限。我们还将探讨 ACCOUNTADMIN(帐户管理员)角色的其他用法,该角色在前面的实验中已简要介绍。
假设一个初级 DBA 加入了 Citi Bike,我们希望为他们创建一个新角色,其权限低于系统定义的默认角色 SYSADMIN。
基于角色的访问控制Snowflake 提供了非常强大且精细的访问控制,它决定了用户可以访问的对象和功能,以及他们拥有的访问级别。有关更多详细信息,请查看 Snowflake 文档。
创建新角色并添加用户
在工作表中,切换到 ACCOUNTADMIN 角色以创建新角色。ACCOUNTADMIN 封装了SYSADMIN 和 SECURITYADMIN 系统定义的角色。它是账户中的顶级角色,应仅授予有限数量的用户。
运行以下命令
1 | use role accountadmin; |
请注意,在工作表的右上角,已更改为 ACCOUNTADMIN:
在将角色用于访问控制之前,必须至少为其分配一个用户。因此,让我们创建一个名为 Snowflake 的新角色,并将其分配给您的 Snowflake 用户。
使用以下命令创建角色并将其分配给您。在运行 GRANT ROLE 命令之前,请将YOUR_USERNAME_GOES_HERE替换为您的用户名:
1 | create role junior_dba; |
如果尝试在 SYSADMIN 等角色中执行此操作,则会因权限不足而失败。默认情况下(和设计),SYSADMIN 角色无法创建新角色或用户。
将工作表上下文更改为新角色JUNIOR_DBA
1 | use role junior_dba; |
请注意,在工作表的右上角已更改为JUNIOR_DBA
此外,由于新创建的角色对任何仓库都没有使用权限,因此未选择仓库。让我们通过切换回 ADMIN 角色并授予仓库使用权限:
1 | use role accountadmin; |
切换回角色。您现在应该可以使用JUNIOR_DBA和COMPUTE_WH。
1 | use role junior_dba; |
最后,您可以注意到,在左侧的数据库对象面板中,不再显示数据库。这是因为该角色没有访问它们的权限。
切换回 ACCOUNTADMIN 角色,并授予查看和使用 and 数据库所需的 USAGE 权限:
1 | use role accountadmin; |
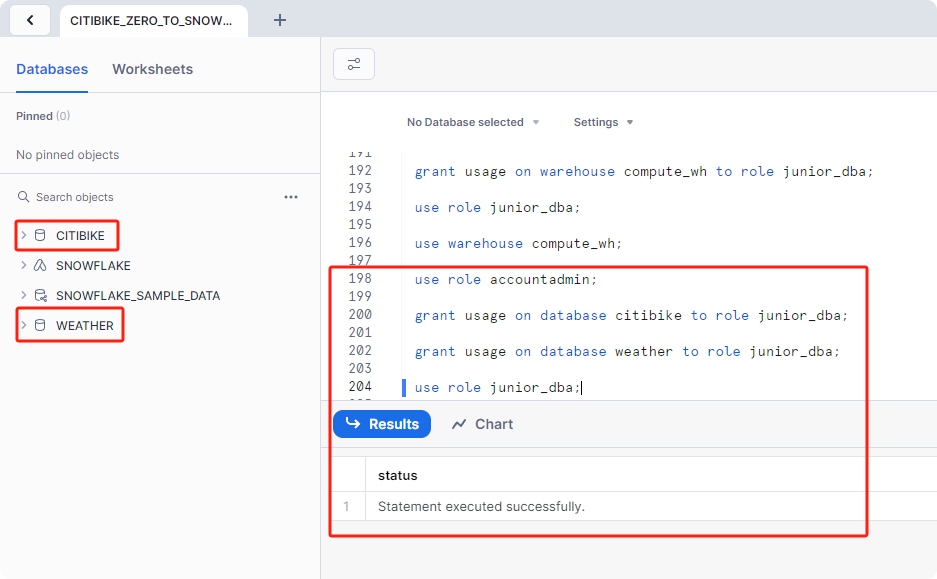
数据库现在显示在左侧的数据库对象浏览器面板中。如果它们未出现,请尝试单击面板中的···,然后单击Refresh
查看帐户管理员 UI
让我们将访问控制角色改回,以查看只有此角色才能访问的 UI 的其他区域。但是,若要执行此任务,请使用 UI 而不是工作表。
首先,点击主页工作表左下角的图标。然后单击您的姓名以显示用户首选项菜单。在菜单中,转到Switch Role,然后选择ACCOUNTADMIN。
为什么我们使用用户首选项菜单而不是工作表来更改角色?UI 会话和每个工作UI 会话和每个工作表都有它们自己独立的角色。UI 会话角色控制您在用户界面中可以看到和访问的元素,而工作表角色仅控制您可以在该角色内访问的对象和操作。

Sharing Data Securely & the Data Marketplace
略